https://colab.research.google.com/If you see a blue "Sign In" button at the top right, click it and log into a Google account.
From the menu, click File, "New notebook".
import torch
from transformers import BertTokenizer, BertModel
# Logging provides more information on what's happening
import logging
logging.basicConfig(level=logging.INFO)
import matplotlib.pyplot as plt
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
list(tokenizer.vocab.keys())[2000:2020]
text = "[CLS] After stealing money from the bank vault, the bank robber " \
"was seen fishing on the Mississippi river bank. [SEP]"
# Split the sentence into tokens.
tokenized_text = tokenizer.tokenize(text)
# Map the token strings to their vocabulary indices.
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# Display the words with their indices.
for tup in zip(tokenized_text, indexed_tokens):
print('{:<12} {:>6,}'.format(tup[0], tup[1]))
# Mark each of the 22 tokens as belonging to sentence "1".
segments_ids = [1] * len(tokenized_text)

# Convert inputs to PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
# Load pre-trained model (weights)
model = BertModel.from_pretrained('bert-base-uncased',
output_hidden_states = True, # Whether the model returns all hidden-states.
)
# Put the model in "evaluation" mode, meaning feed-forward operation.
model.eval()
# Run the text through BERT, and collect all of the hidden states produced
# from all 12 layers.
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensors)
# Evaluating the model will return a different number of objects based on
# how it's configured in the `from_pretrained` call earlier. In this case,
# becase we set `output_hidden_states = True`, the third item will be the
# hidden states from all layers. See the documentation for more details:
# https://huggingface.co/transformers/model_doc/bert.html#bertmodel
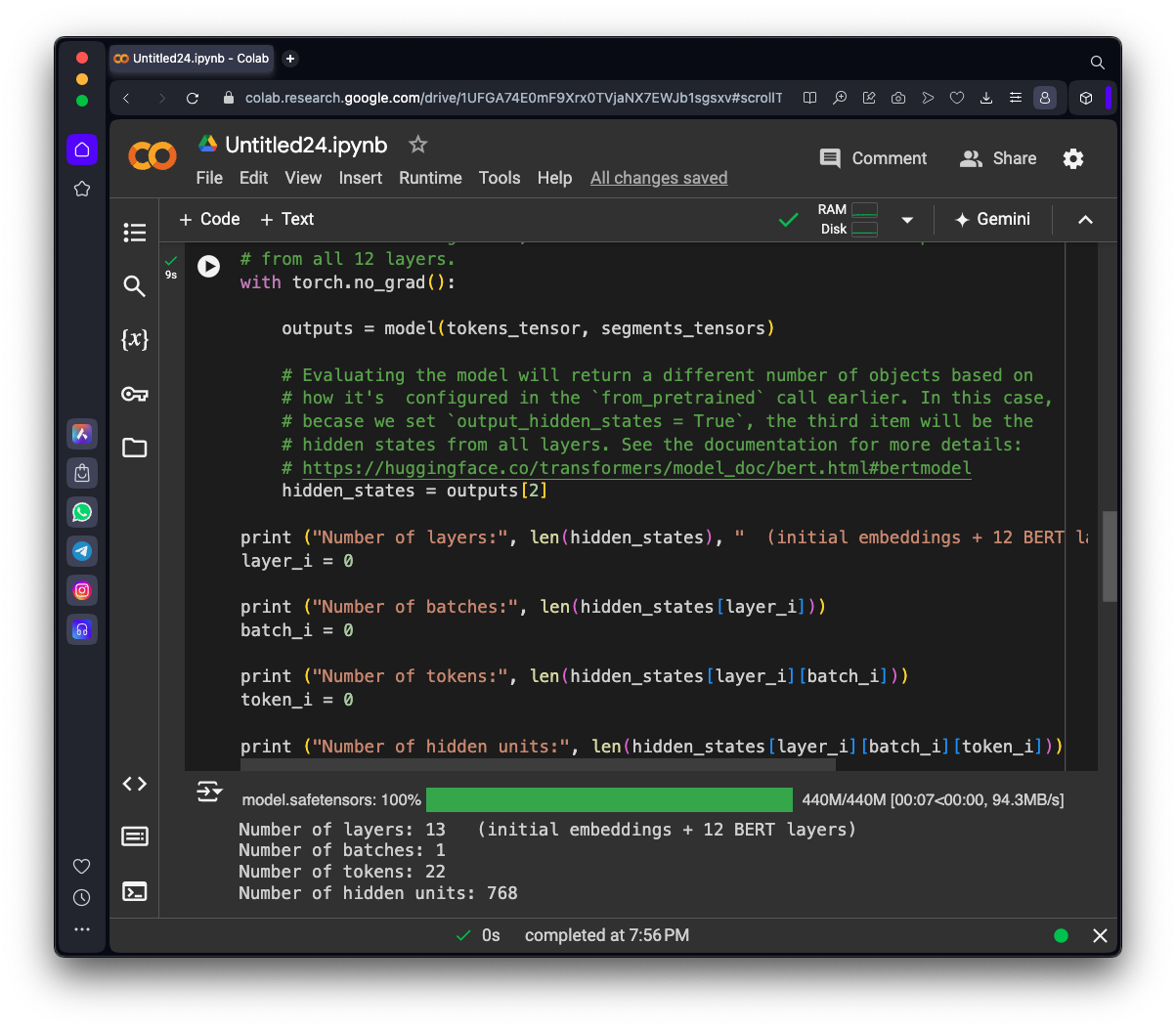
hidden_states = outputs[2]
print ("Number of layers:", len(hidden_states), " (initial embeddings + 12 BERT layers)")
layer_i = 0
print ("Number of batches:", len(hidden_states[layer_i]))
batch_i = 0
print ("Number of tokens:", len(hidden_states[layer_i][batch_i]))
token_i = 0
print ("Number of hidden units:", len(hidden_states[layer_i][batch_i][token_i]))
# Concatenate the tensors for all layers. We use `stack` here to
# create a new dimension in the tensor.
token_embeddings = torch.stack(hidden_states, dim=0)
# Remove dimension 1, the "batches".
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# Swap dimensions 0 and 1.
token_embeddings = token_embeddings.permute(1,0,2)
# Stores the token vectors, with shape [22 x 768]
token_vecs_sum = []
# `token_embeddings` is a [22 x 12 x 768] tensor.
# For each token in the sentence...
for token in token_embeddings:
# `token` is a [12 x 768] tensor
# Sum the vectors from the last four layers.
sum_vec = torch.sum(token[-4:], dim=0)
# Use `sum_vec` to represent `token`.
token_vecs_sum.append(sum_vec)
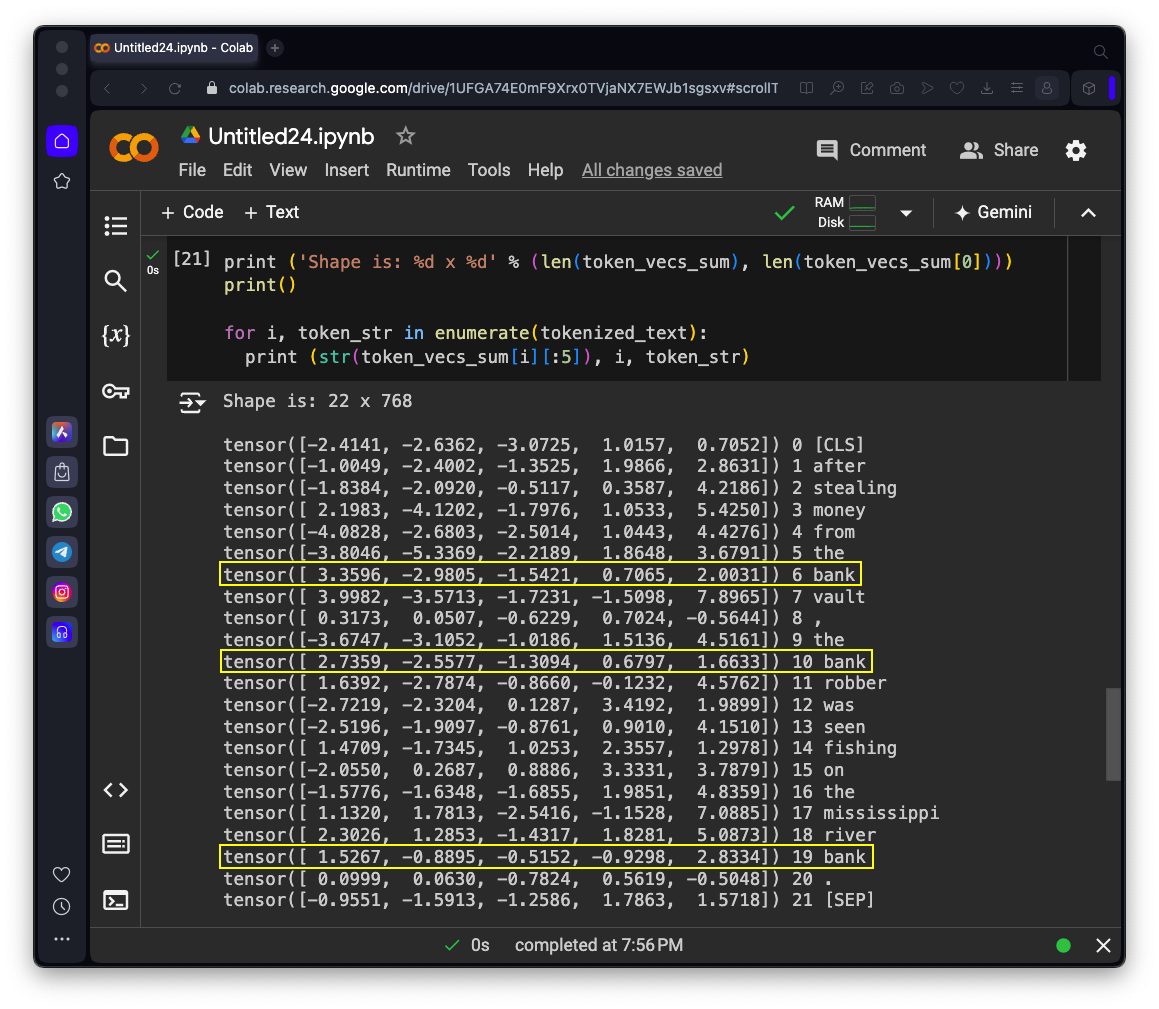
print ('Shape is: %d x %d' % (len(token_vecs_sum), len(token_vecs_sum[0])))
print()
for i, token_str in enumerate(tokenized_text):
print (str(token_vecs_sum[i][:5]), i, token_str)
The first five values in each vector are shown, followed by the index, and the word that vector represents.
Compare the three vectors for "bank", outlined in yellow in the image below.
The first two "bank" vectors begin with a value near 3, and then have a value near -3, but the last one starts with 1.5 followed by -0.9. These vectors seem very different, as they should be, since the meaning of the last "bank" in context is not the same as the other two.
ML 129.1: Comparing Vectors (10 pts.)
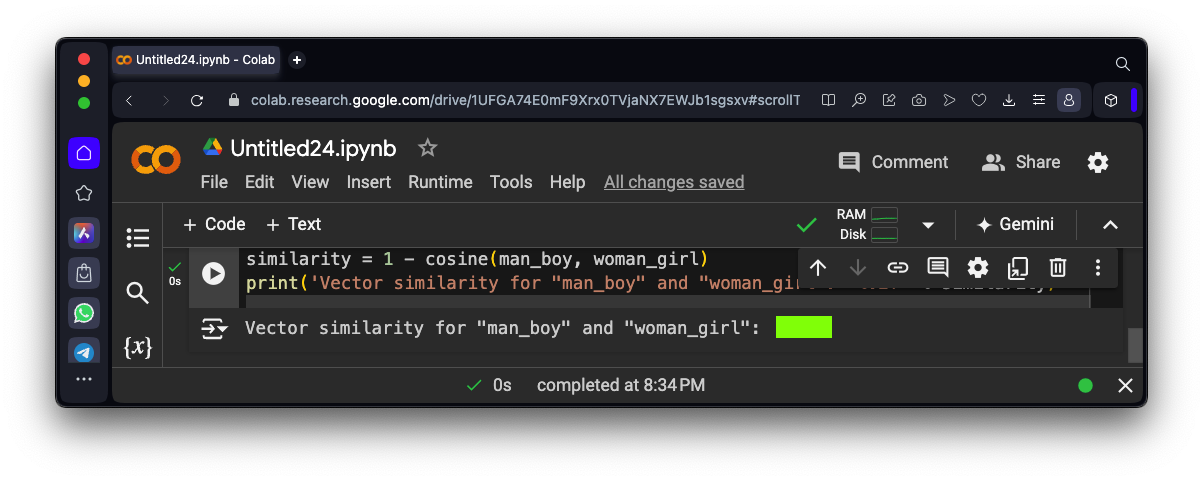
Execute this code to calculate the cosine of the angle between pairs of vectors. The cosine is 1 if the vectors are identical, and a smaller value if they differ.As shown below, the vectors for two "bank" words with the same meaning are similar (0.94), but when the two words have different meanings, the two vectors differ more, so the similarity is lower: 0.69.from scipy.spatial.distance import cosine # Calculate the cosine similarity between the word bank # in "bank robber" vs "river bank" (different meanings). diff_bank = 1 - cosine(token_vecs_sum[10], token_vecs_sum[19]) print('Vector similarity for *different* meanings of "bank": %.2f' % diff_bank) # Calculate the cosine similarity between the word bank # in "bank robber" vs "bank vault" (same meaning). same_bank = 1 - cosine(token_vecs_sum[10], token_vecs_sum[6]) print('Vector similarity for *similar* meanings of "bank": %.2f' % same_bank) # Calculate the cosine similarity between two totally different # words: "stealing" and "river" totally_different = 1 - cosine(token_vecs_sum[2], token_vecs_sum[18]) print('Vector similarity for "stealing" and "river": %.2f' % totally_different)The flag is covered by a green rectangle in the image below.
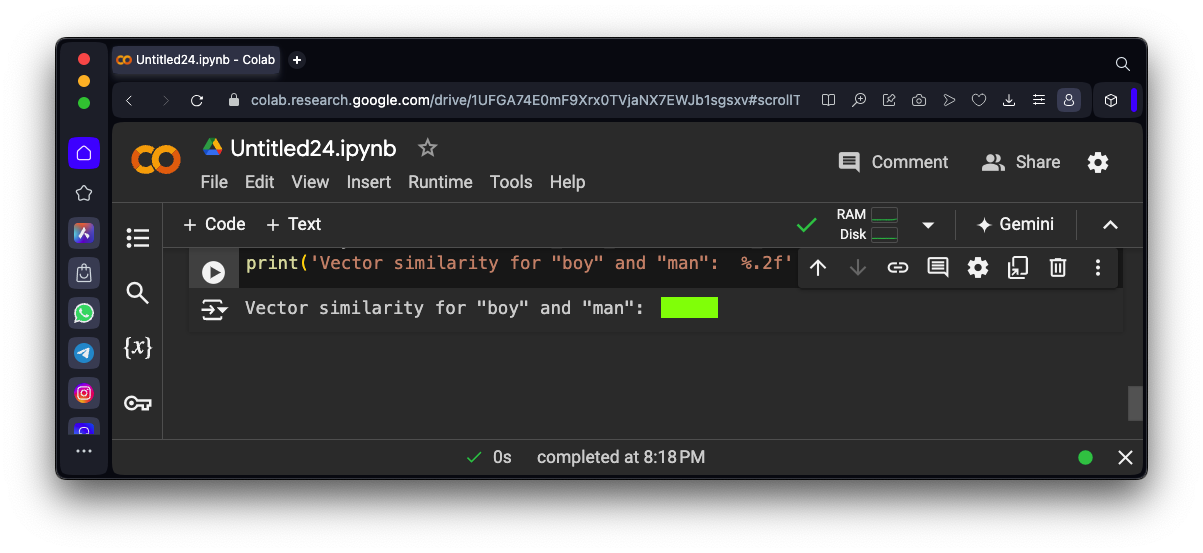
ML 129.2: Boys to Men (10 pts)
Calculate vectors for this sentence:A boy becomes a man, and a girl becomes a woman.Calculate the cosine difference between "boy" and "man".The flag is covered by a green rectangle in the image below.
ML 129.3: Growing Up (20 pts)
Use the same sentence as in the challenge above.Calculate the difference vector between "boy" and "man".
Also calculate the difference vector between "girl" and "woman".
Calculate the cosine difference between those two difference vectors.
The flag is covered by a green rectangle in the image below.
ML 129.4: Synonyms (10 pts)
Calculate vectors for this sentence:Find the synonyms in this list:Calculate the cosine difference between "monitor" and each of the other words.
man, woman, camera, monitor, elephant, cow, footstool, battery, amazing, awful,
phone, computer, display.The flag is covered by a green rectangle in the image below.
Posted 7-6-24
Image and code for ML 129.1 updated on 7-24-24
Flag 4 added 7-26-24