As detailed below, BERT learns by predicting masked words from context (the words before and after it), and by recognizing whether sentences are in the correct order. This creates an encoding system that assigns a multidimensional vector value to each word, corresponding to that word's meaning in relation to other words.
BERT reduces information written in pargraphs of natural language to numerical vectors which can be easily used to perform many tasks, such as generating more text, translating languages, summarizing text, or categorizing text (sentiment analysis).
https://colab.research.google.com/If you see a blue "Sign In" button at the top right, click it and log into a Google account.
From the menu, click File, "New notebook".
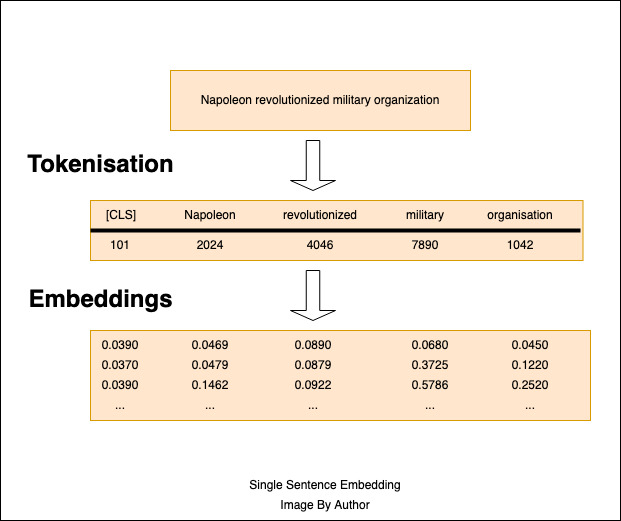
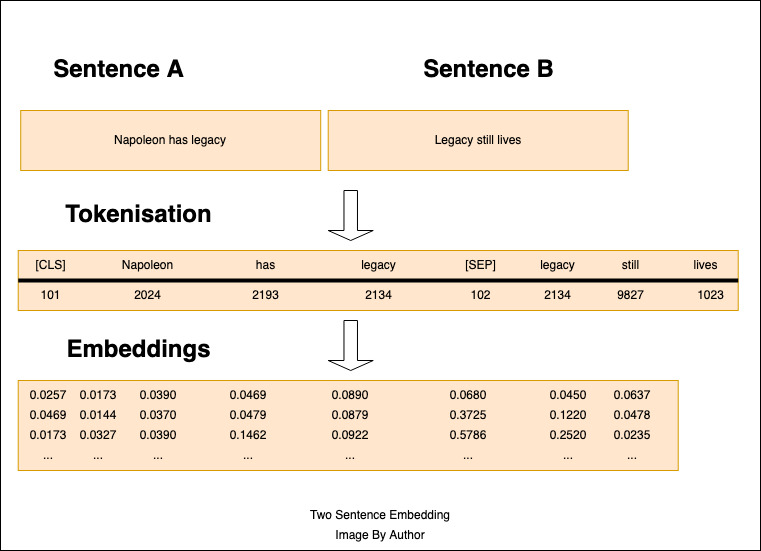
THe tokens are then converted to Embeddings, which are high-dimensional vectors, as shown below.
from transformers import BertTokenizer, BertForMaskedLM
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
text = ("Napoleon revolutionised military organisation. "
"Napoleon has legacy. "
"Legacy still lives. "
)
rep = tokenizer(text, return_tensors = "pt")
words = ("Napoleon", "revolution", "ised", "military", "organisation", ".",
"Napoleon", "has", "legacy", ".", "Legacy", "still", "lives", ".")
tokens = []
for t in rep.input_ids[0]:
tokens.append(int(t))
print()
word_index = 0
for t in tokens:
if int(t) < 150:
print(t)
else:
print(t, "\t", words[word_index])
word_index += 1
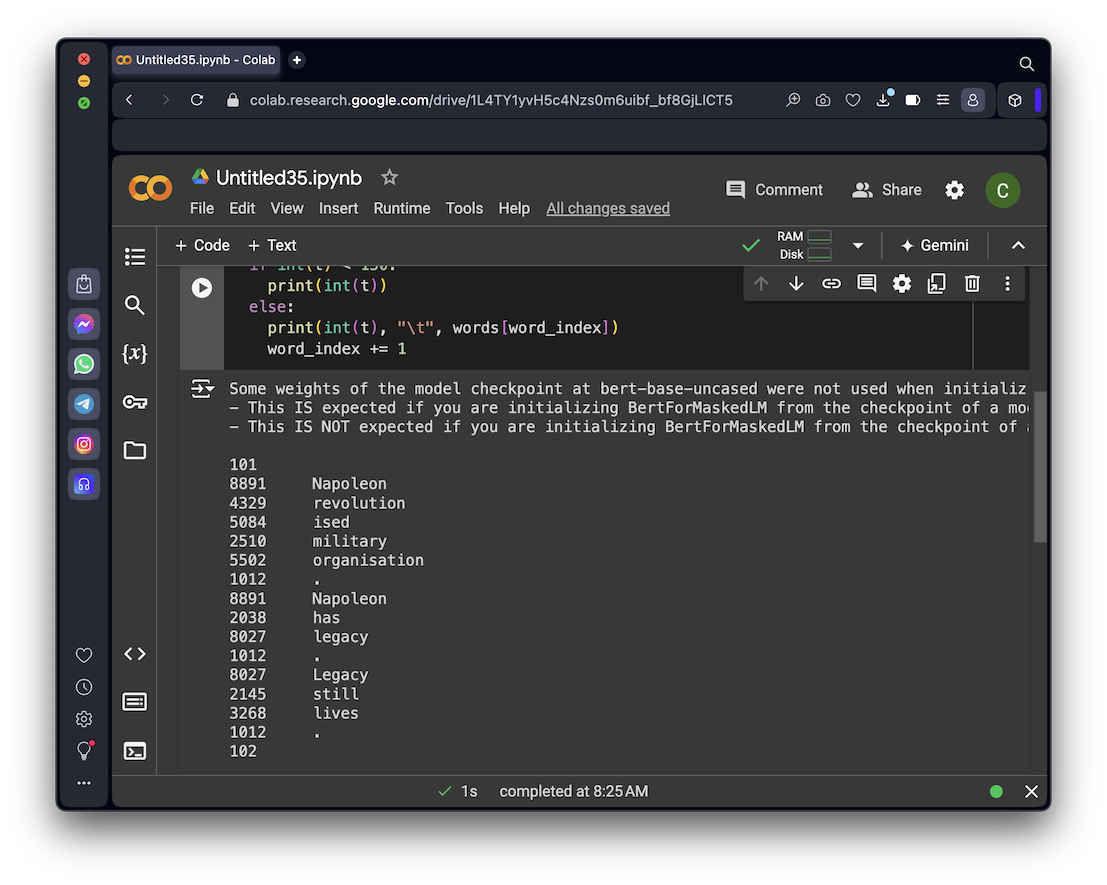
The start and end of the text is marked by the tokens 101 and 102.
Execute the code below to see an example of masking.
from transformers import BertTokenizer, BertForMaskedLM
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
text = ("Napoleon revolutionised military organisation. "
"Napoleon has legacy. "
"Legacy still lives. "
)
rep = tokenizer(text, return_tensors = "pt")
words = ("Napoleon", "revolution", "ised", "military", "organisation", ".",
"Napoleon", "has", "legacy", ".", "Legacy", "still", "lives", ".")
tokens = []
for t in rep.input_ids[0]:
tokens.append(int(t))
# Mask 15% of the tokens randomly
rand = torch.rand(rep.input_ids.shape)
mask_arr = (rand < 0.15) * (rep.input_ids != 101) * (rep.input_ids != 102)
selection = torch.flatten(mask_arr[0].nonzero()).tolist()
rep.input_ids[0, selection] = 103
after_masking = rep.input_ids
masked_tokens = []
for t in after_masking[0]:
masked_tokens.append(int(t))
print()
print("Token", "\t", "Masked")
word_index = 0
for (t, a) in zip(tokens, masked_tokens):
if int(t) < 150:
print(t)
else:
print(t, "\t", a, "\t", words[word_index])
word_index += 1
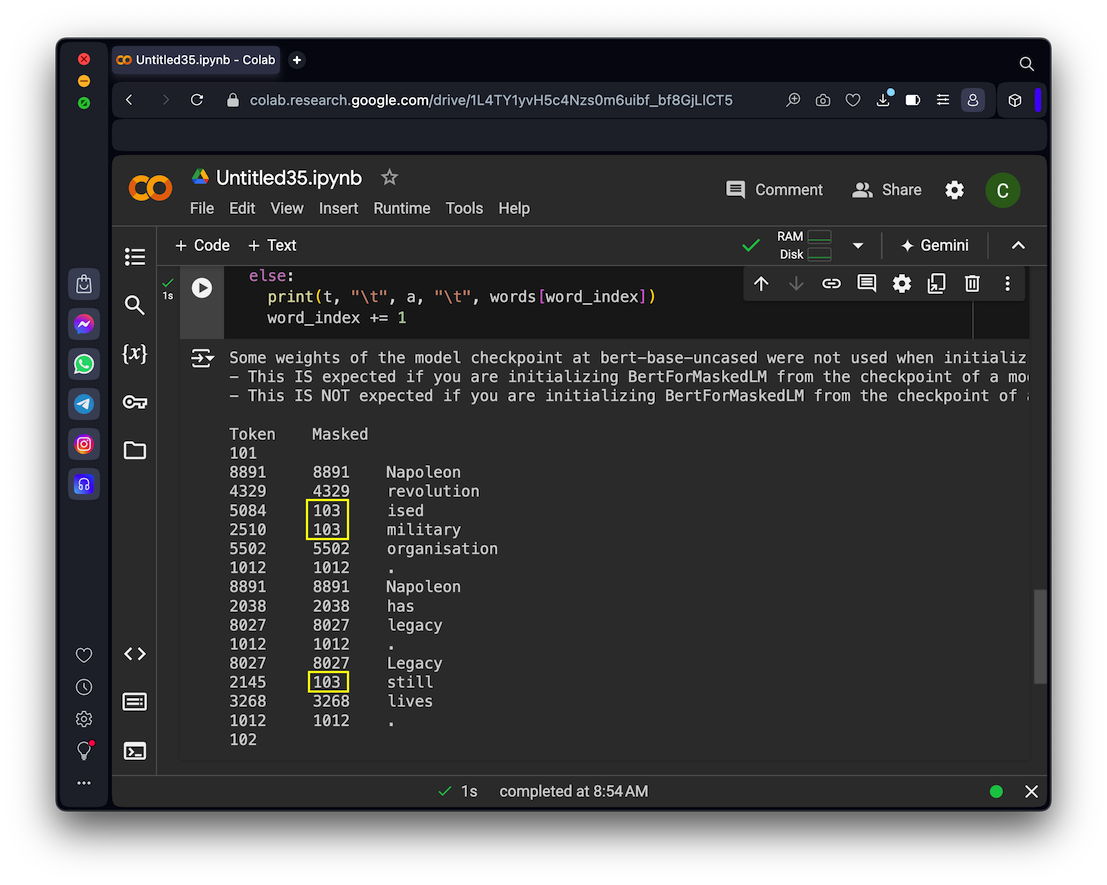
If you don't see any masked tokens, run the code again.
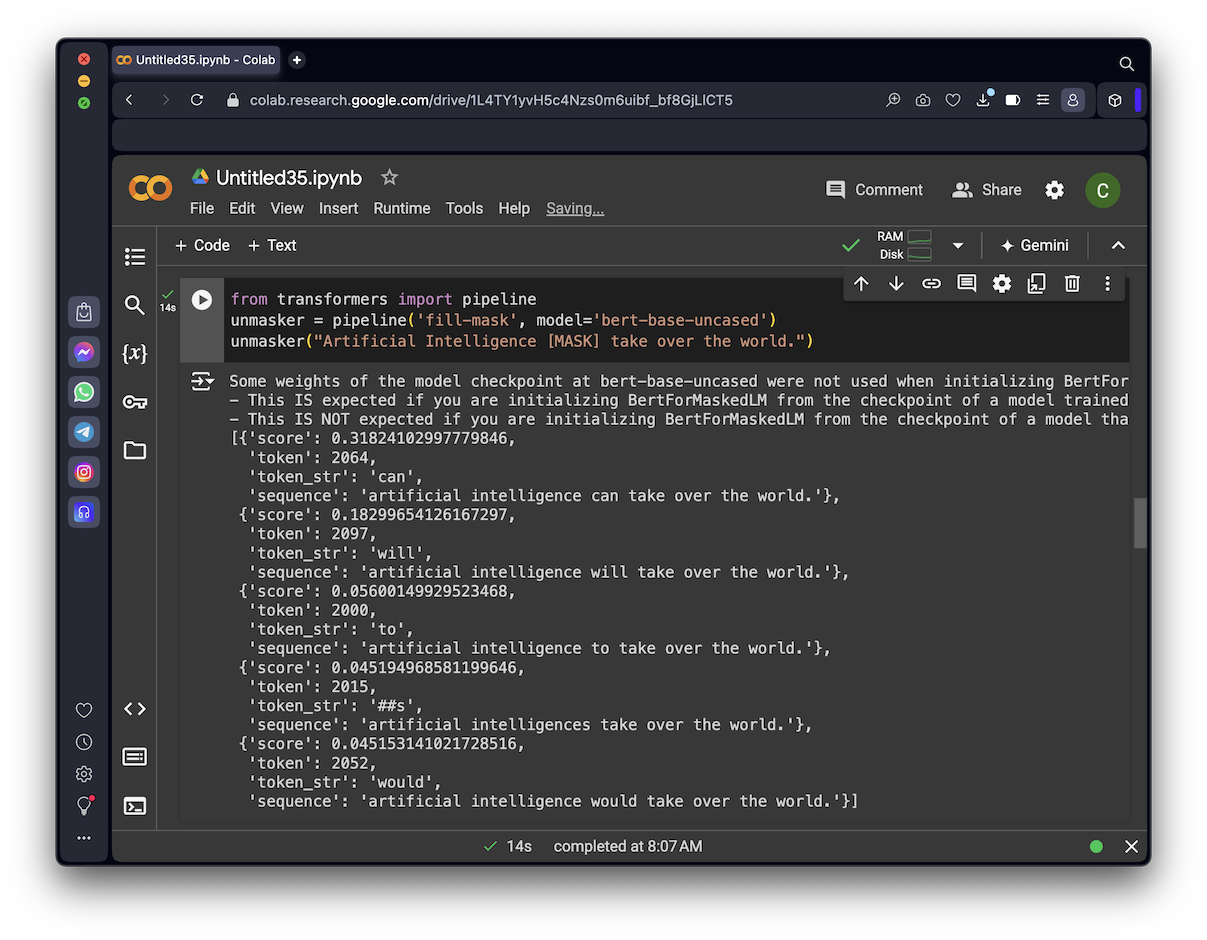
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")
As shown below, [CLS] and [SEP] tokens indicate the start and end of the first sentence, and each token is embedded in a multidimensional vector. The embedding is done by a neural net, which is trained to correctly predict masked words, and also to correctly recognize sentences that are out of order.
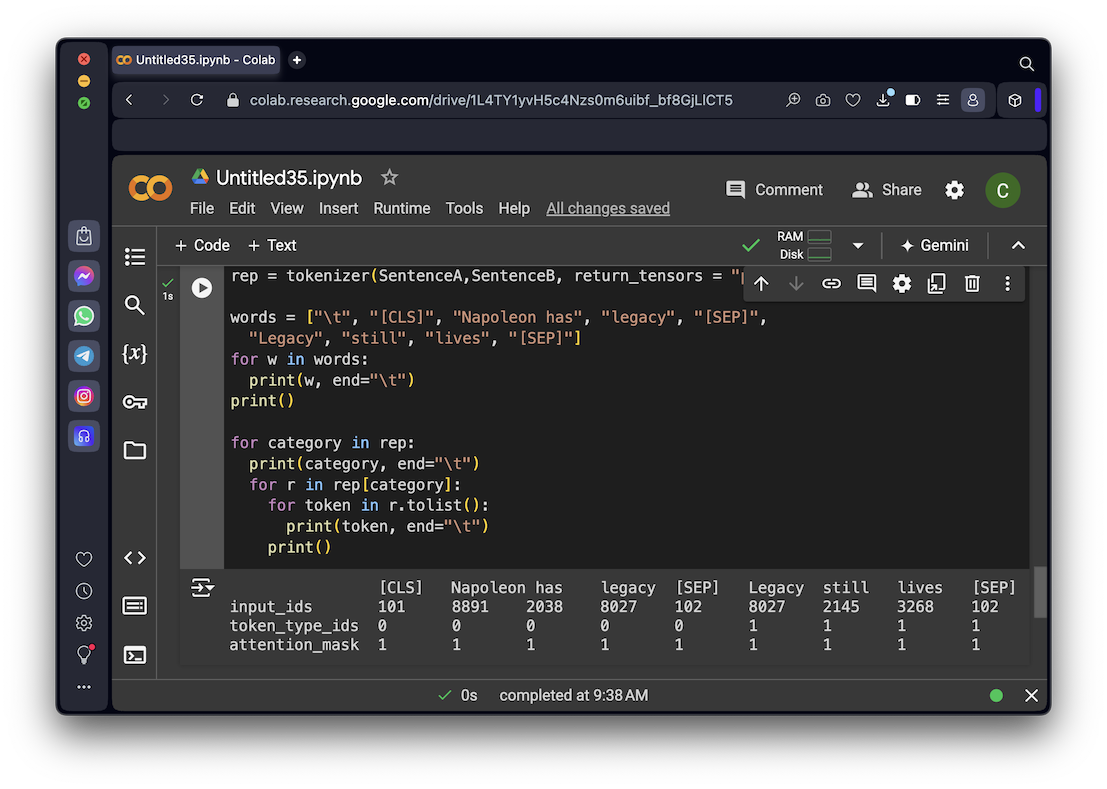
from transformers import BertTokenizer, BertForNextSentencePrediction
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
SentenceA = ("Napoleon has legacy")
SentenceB = ("Legacy still lives")
rep = tokenizer(SentenceA,SentenceB, return_tensors = "pt")
words = ["\t", "[CLS]", "Napoleon has", "legacy", "[SEP]",
"Legacy", "still", "lives", "[SEP]"]
for w in words:
print(w, end="\t")
print()
for category in rep:
print(category, end="\t")
for r in rep[category]:
for token in r.tolist():
print(token, end="\t")
print()
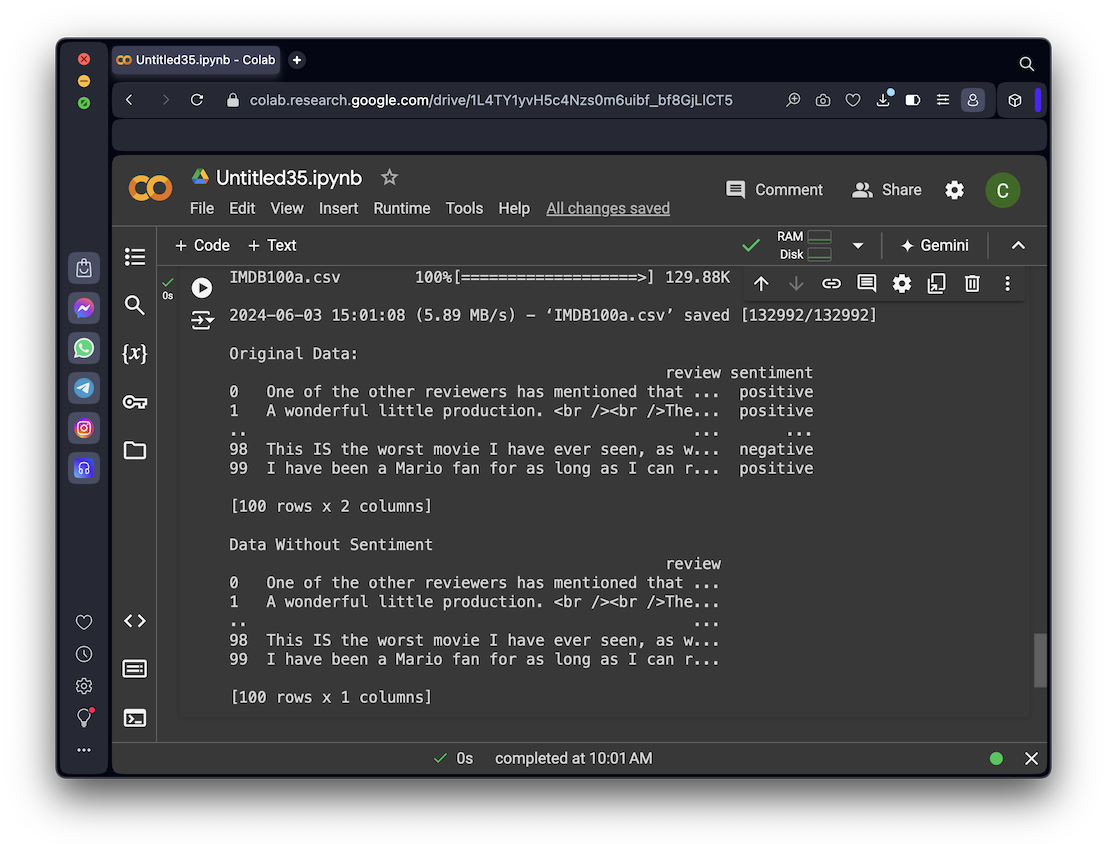
I made a smaller list of 100 movie reviews, just to make the project run faster.
Execute this code to download the data:
!wget https://samsclass.info/ML/proj/IMDB100a.csv
import pandas as pd
pd.set_option('display.max_rows', 4)
df_orig = pd.read_csv('IMDB100a.csv')
print("Original Data:")
print(df_orig)
df = df_orig.drop('sentiment', axis=1)
print()
print("Data Without Sentiment")
print(df)
We'll send the "Data Without Sentiment" to a pretrained BERT model to see how well it can decide whether the review is positive or negative.
import torch
import numpy as np
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
model = BertForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
def sentiment_movie_score(movie_review):
token = tokenizer.encode(movie_review, return_tensors = 'pt')
result = model(token)
return int(torch.argmax(result.logits))+1
df['sentiment'] = df['review'].apply(lambda x: sentiment_movie_score(x[:512]))
print(df)
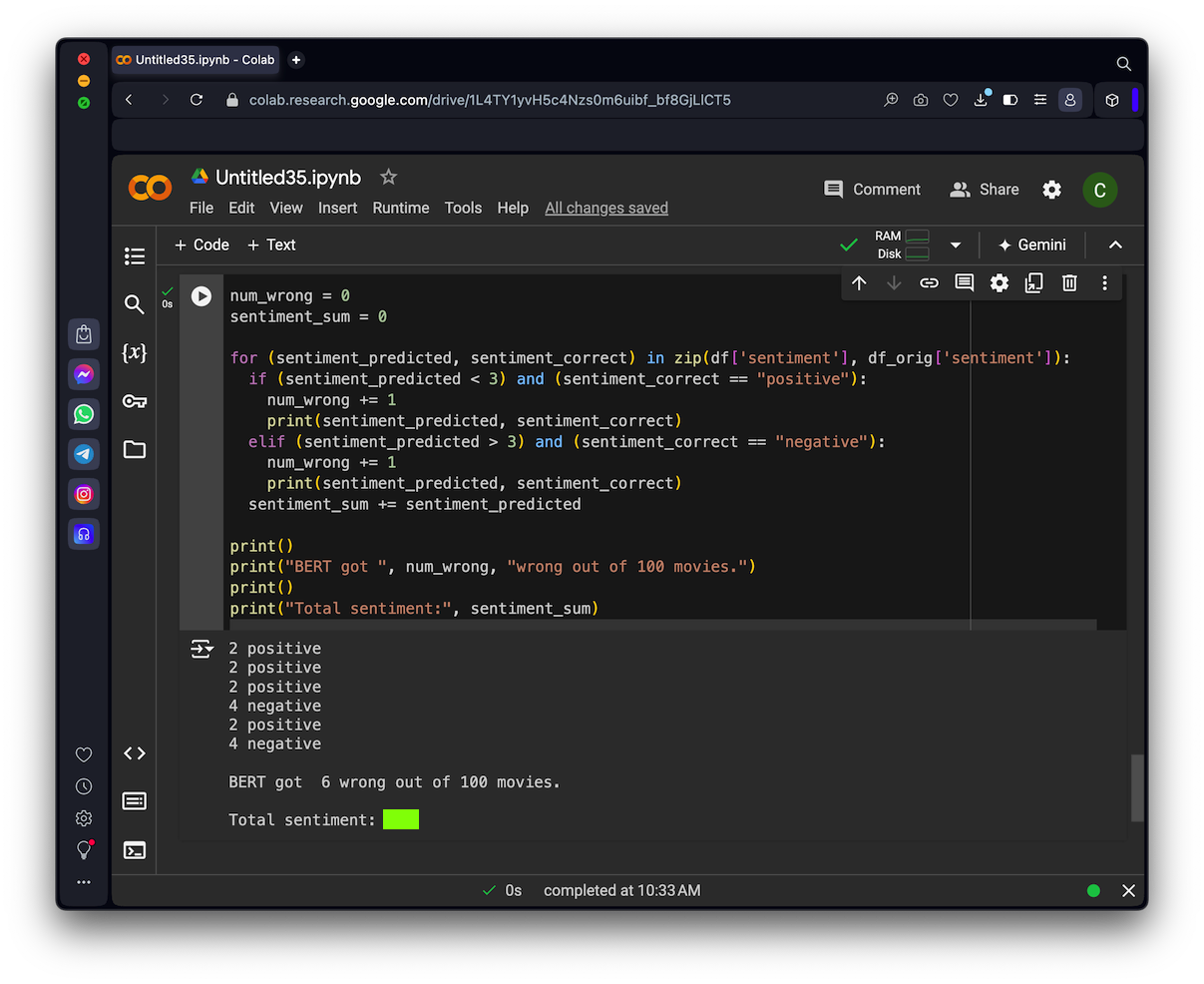
num_wrong = 0
sentiment_sum = 0
for (sentiment_predicted, sentiment_correct) in zip(df['sentiment'], df_orig['sentiment']):
if (sentiment_predicted < 3) and (sentiment_correct == "positive"):
num_wrong += 1
print(sentiment_predicted, sentiment_correct)
elif (sentiment_predicted > 3) and (sentiment_correct == "negative"):
num_wrong += 1
print(sentiment_predicted, sentiment_correct)
sentiment_sum += sentiment_predicted
print()
print("BERT got ", num_wrong, "wrong out of 100 movies.")
print()
print("Total sentiment:", sentiment_sum)
ML 127.1: Sum of Sentiments (10 pts)
The flag is covered by a green rectangle in the image below.
How to Fine-Tune BERT for Sentiment Analysis with Hugging Face Transformers
Fine Tuning BERT for Sentiment Analysis
BERT 101 - State Of The Art NLP Model Explained
Posted 6-3-24
Masked word prediction added 6-4-24