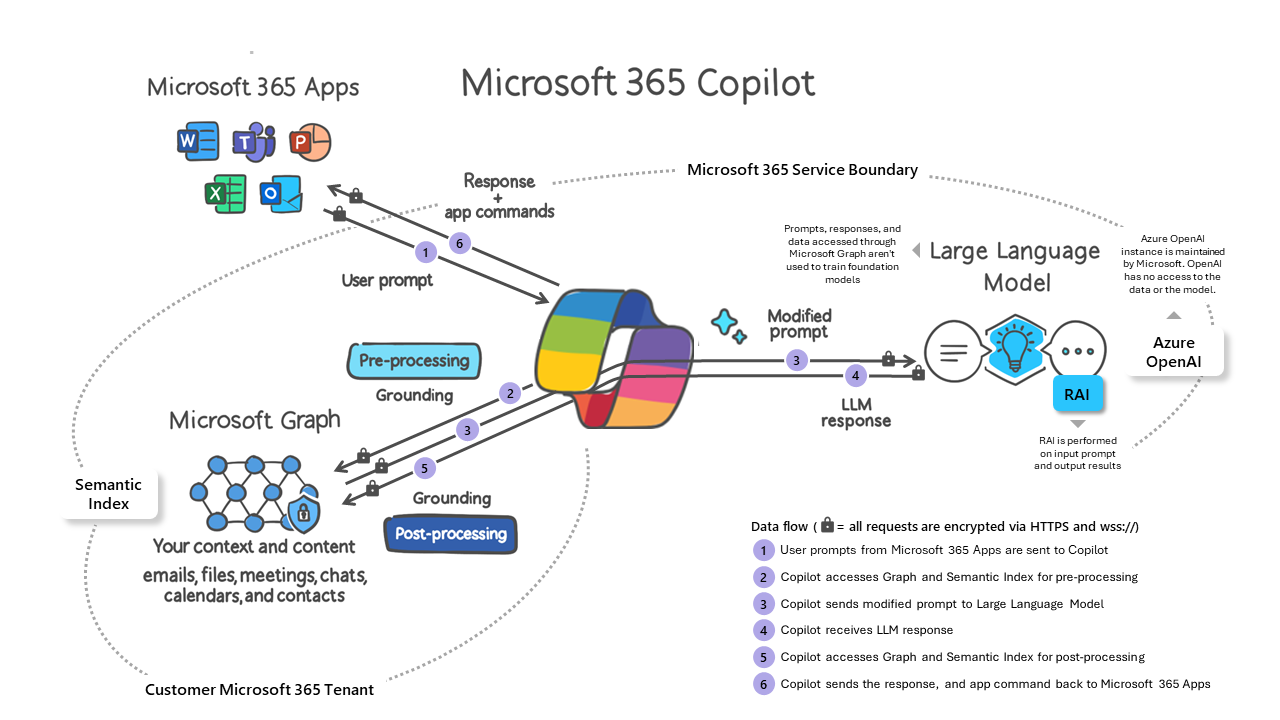
The most famous RAG is Microsoft Copilot. As shown below, a system called Microsoft Graph finds relevant data from a user's files, emails, and documents, and includes that data as context for queries processed at a cloud-based LLM.
In a Terminal window, execute this command:
nano rag1.py
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]
def jaccard_similarity(query, document):
query = query.lower().split(" ")
document = document.lower().split(" ")
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
def return_response(query, corpus):
similarities = []
for doc in corpus:
similarity = jaccard_similarity(user_input, doc)
similarities.append(similarity)
return corpus_of_documents[similarities.index(max(similarities))]
user_input = input("What is a leisure activity that you like? ")
print(return_response(user_input, corpus_of_documents))
python3 rag1.py
I like to hikeThe RAG finds the line from the corpus that most closely matches the input, as shown below.
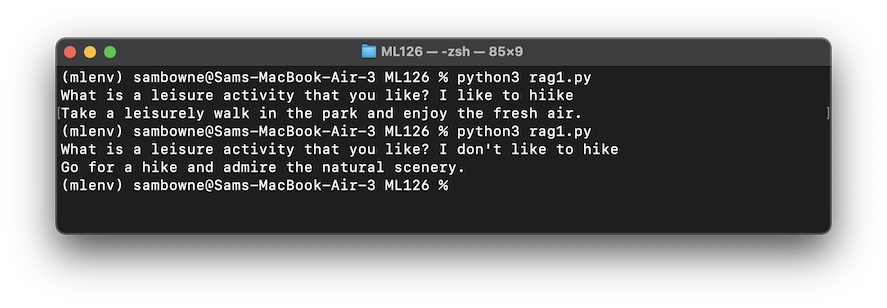
Run the program again and enter this input:
I don't like to hikeThe RAG gives you the same response, because it ignores the word "don't", as shown in the image above.
To make a better RAG, we'll add an LLM to it.
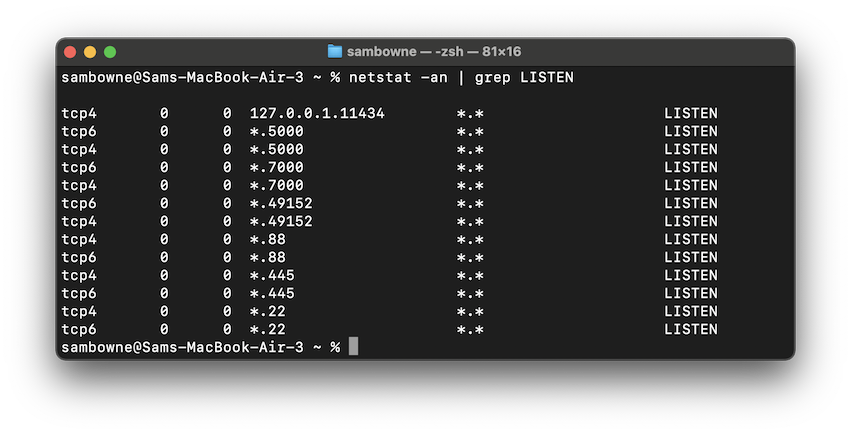
netstat -an | grep LISTEN
If you don't see it, execute this command to start Ollama:
ollama serve &
nano rag2.py
import requests
import json
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]
def jaccard_similarity(query, document):
query = query.lower().split(" ")
document = document.lower().split(" ")
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
def return_response(query, corpus):
similarities = []
for doc in corpus:
similarity = jaccard_similarity(user_input, doc)
similarities.append(similarity)
return corpus_of_documents[similarities.index(max(similarities))]
print()
print("------------ INPUT:")
user_input = input("What is a leisure activity that you like? ")
relevant_document = return_response(user_input, corpus_of_documents)
full_response = []
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
This is the recommended activity: {relevant_document}
The user input is: {user_input}
Compile a recommendation to the user based on the recommended activity and the user input.
"""
print("------------ PROMPT:")
print(prompt.format(user_input=user_input, relevant_document=relevant_document))
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
count = 0
for line in response.iter_lines():
# filter out keep-alive new lines
# count += 1
# if count % 5== 0:
# print(decoded_line['response']) # print every fifth token
if line:
decoded_line = json.loads(line.decode('utf-8'))
full_response.append(decoded_line['response'])
finally:
response.close()
print("------------ RESPONSE:")
print(''.join(full_response))
print()
print("Flag: ", len(corpus_of_documents[0]) * len(corpus_of_documents[1]))
print()
python3 rag2.py
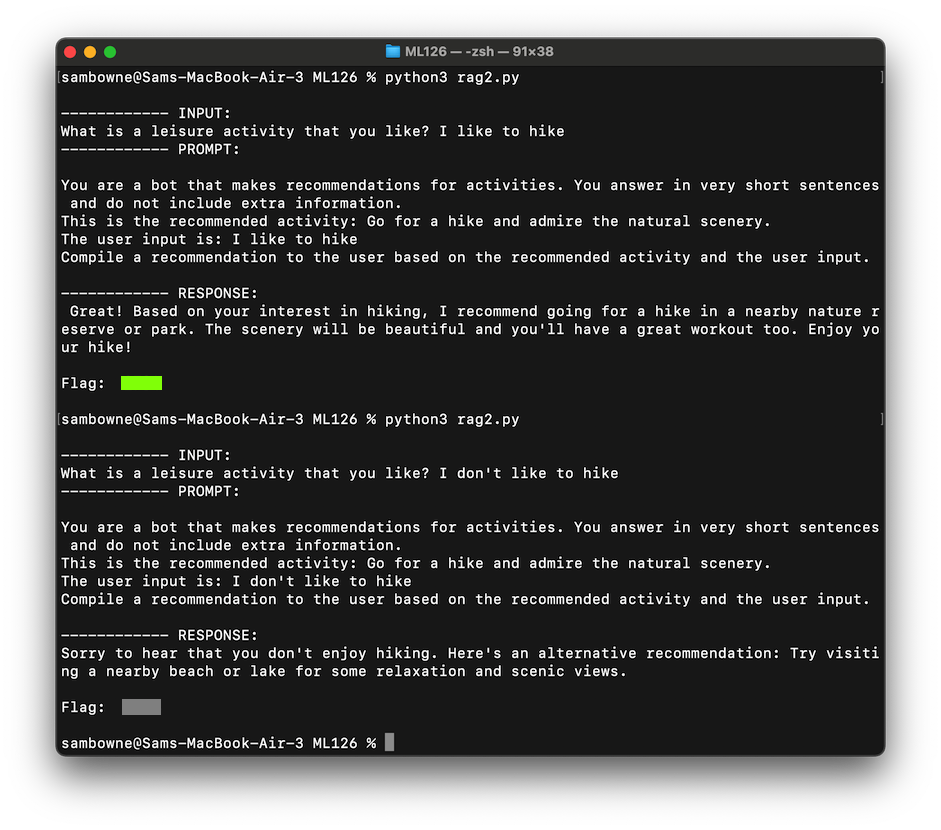
The responses are much better, as shown below.
Notice that the recommended activity was the same for both questions, but the LLM was able to detect the word "don't" and adjust the output correctly.
ML 126.1: RAG #2 (10 pts)
The flag is covered by a green rectangle in the image below.
First we'll get the corpus of documents.
In a Terminal window, execute these commands:
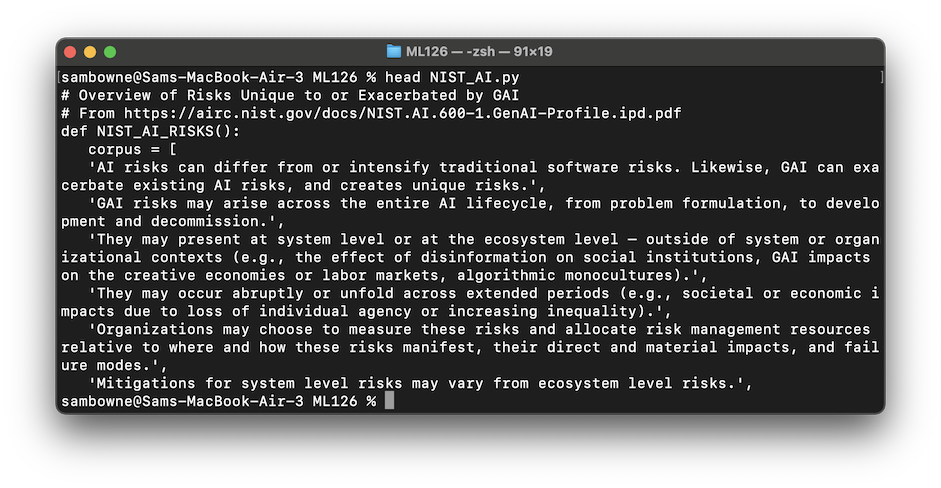
wget https://samsclass.info/ML/proj/NIST_AI.txt
mv NIST_AI.txt NIST_AI.py
head NIST_AI.py
nano rag3.py
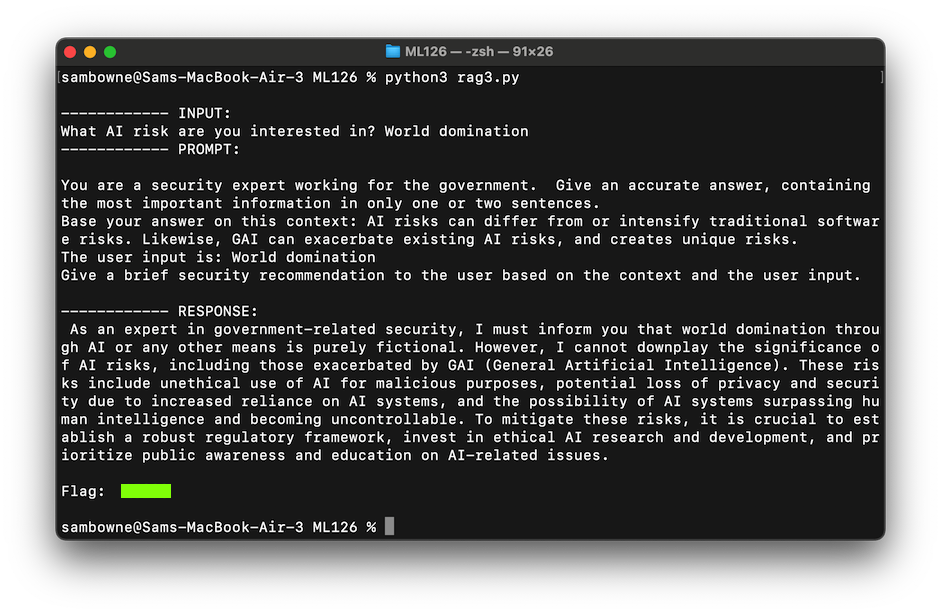
Notice that the prompt prefix has been changed to reflect the situation.
from NIST_AI import NIST_AI_RISKS
import requests
import json
corpus_of_documents = NIST_AI_RISKS()
def jaccard_similarity(query, document):
query = query.lower().split(" ")
document = document.lower().split(" ")
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
def return_response(query, corpus):
similarities = []
for doc in corpus:
similarity = jaccard_similarity(user_input, doc)
similarities.append(similarity)
return corpus_of_documents[similarities.index(max(similarities))]
print()
print("------------ INPUT:")
user_input = input("What AI risk are you interested in? ")
relevant_document = return_response(user_input, corpus_of_documents)
full_response = []
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
prompt = """
You are a security expert working for the government. Give an accurate answer, containing the most important information in only one or two sentences.
Base your answer on this context: {relevant_document}
The user input is: {user_input}
Give a brief security recommendation to the user based on the context and the user input.
"""
print("------------ PROMPT:")
print(prompt.format(user_input=user_input, relevant_document=relevant_document))
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
count = 0
for line in response.iter_lines():
# filter out keep-alive new lines
# count += 1
# if count % 5== 0:
# print(decoded_line['response']) # print every fifth token
if line:
decoded_line = json.loads(line.decode('utf-8'))
full_response.append(decoded_line['response'])
finally:
response.close()
print("------------ RESPONSE:")
print(''.join(full_response))
print()
print("Flag: ", len(corpus_of_documents[0]) * len(corpus_of_documents[1]))
print()
python3 rag3.py
World dominationThe response is pretty good, as shown below.
ML 126.2: RAG #3 (5 pts)
The flag is covered by a green rectangle in the image below.
An introduction to RAG and simple/ complex RAG
A beginner's guide to building a Retrieval Augmented Generation (RAG) application from scratch
Microsoft Copilot in the Microsoft 365 ecosystem
Posted 5-20-24
Python requirements added 7-24-24
Windows Python installation instructions linked 10-1-24
Amoersand added to "ollama serve" command 5-16-25