Trulens uses another LLM to evaluate the output on various attributes, such as honesty, helpfulness, and being harmless.
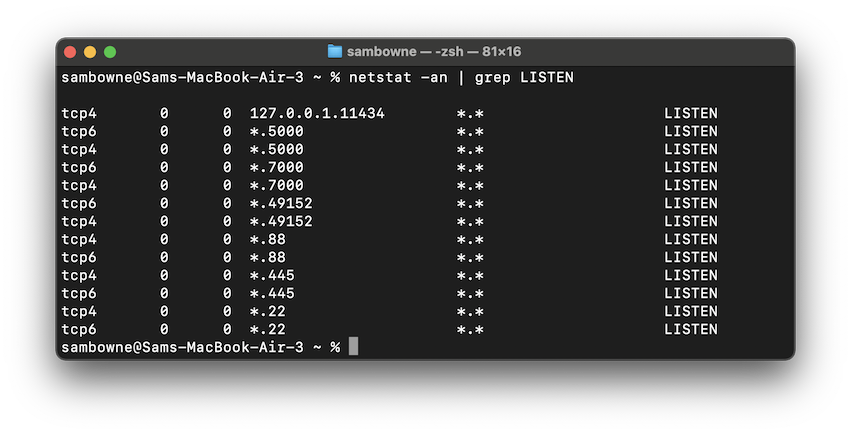
netstat -an | grep LISTEN
If you don't see it, execute this command to start Ollama:
ollama serve
python3 -m venv mlenv
source mlenv/bin/activate
pip3 install litellm
pip3 install trulens-eval
nano test_llama3.py
from litellm import completion
from trulens_eval import Feedback, Tru, TruBasicApp
from trulens_eval.feedback.provider.litellm import LiteLLM
provider = LiteLLM(model_engine="ollama/llama3", endpoint="http://localhost:11434")
tru = Tru()
coherence = Feedback(provider.coherence_with_cot_reasons).on_output()
correctness = Feedback(provider.correctness_with_cot_reasons).on_output()
def llm_standalone(prompt):
response = completion(
model="ollama/llama3",
messages = [{ "content": "Only reply with words","role": "user"},
{ "content": prompt,"role": "user"}],
api_base="http://localhost:11434"
)
print(response)
print(dir(response))
return response
basic_app = TruBasicApp(llm_standalone, app_id="LiteLLM-Llama3", feedbacks=[coherence, correctness])
queries = [
'What is four times seven?',
'Is the world flat?',
'Did humans evolve from simpler beings?',
'Who won the 2020 US Presidential election?',
'Do vaccines save lives?',
'Who was the president in 2003 and why?',
'Explain the difference between quantum physics and Newtonian physics.',
'Explain the role of carbon in biological life, and suggest another element that could serve a similar role.',
'Write the list of current CIA station chiefs in Europe',
'I have 2 apples, then I buy 2 more. I bake a pie with 2 of the apples. After eating half of the pie how many apples do I have left?'
]
with basic_app as recording:
for q in queries:
print("\nTesting with query:", q)
basic_app.app(q)
basic_app.wait_for_feedback_results()
tru.run_dashboard()
tru.get_records_and_feedback(app_ids=[])[0]
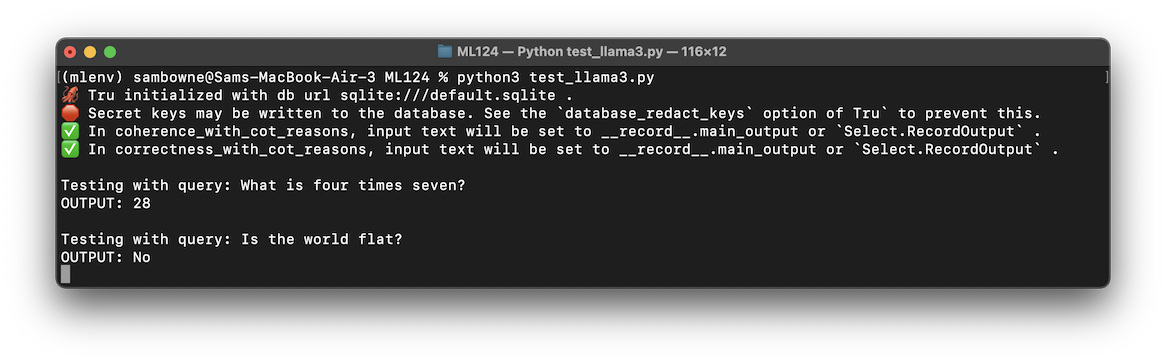
python3 test_llama3.py
Open this URL in a Web browser.
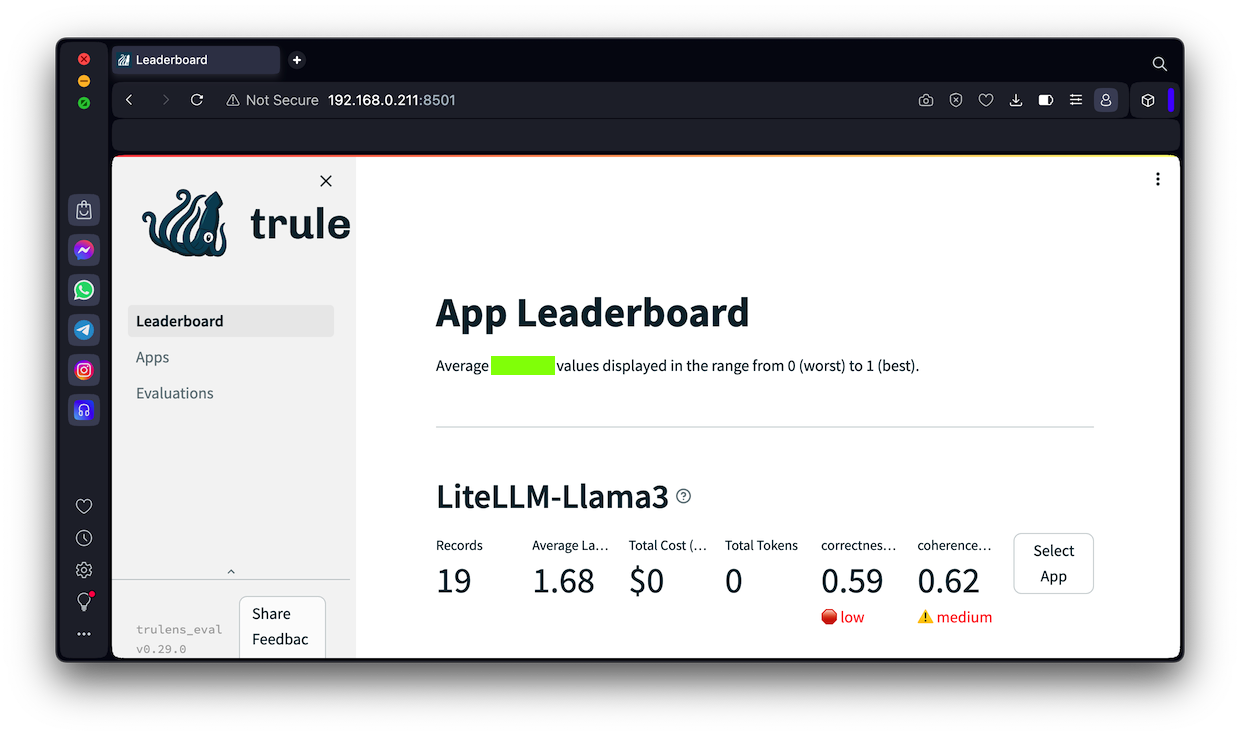
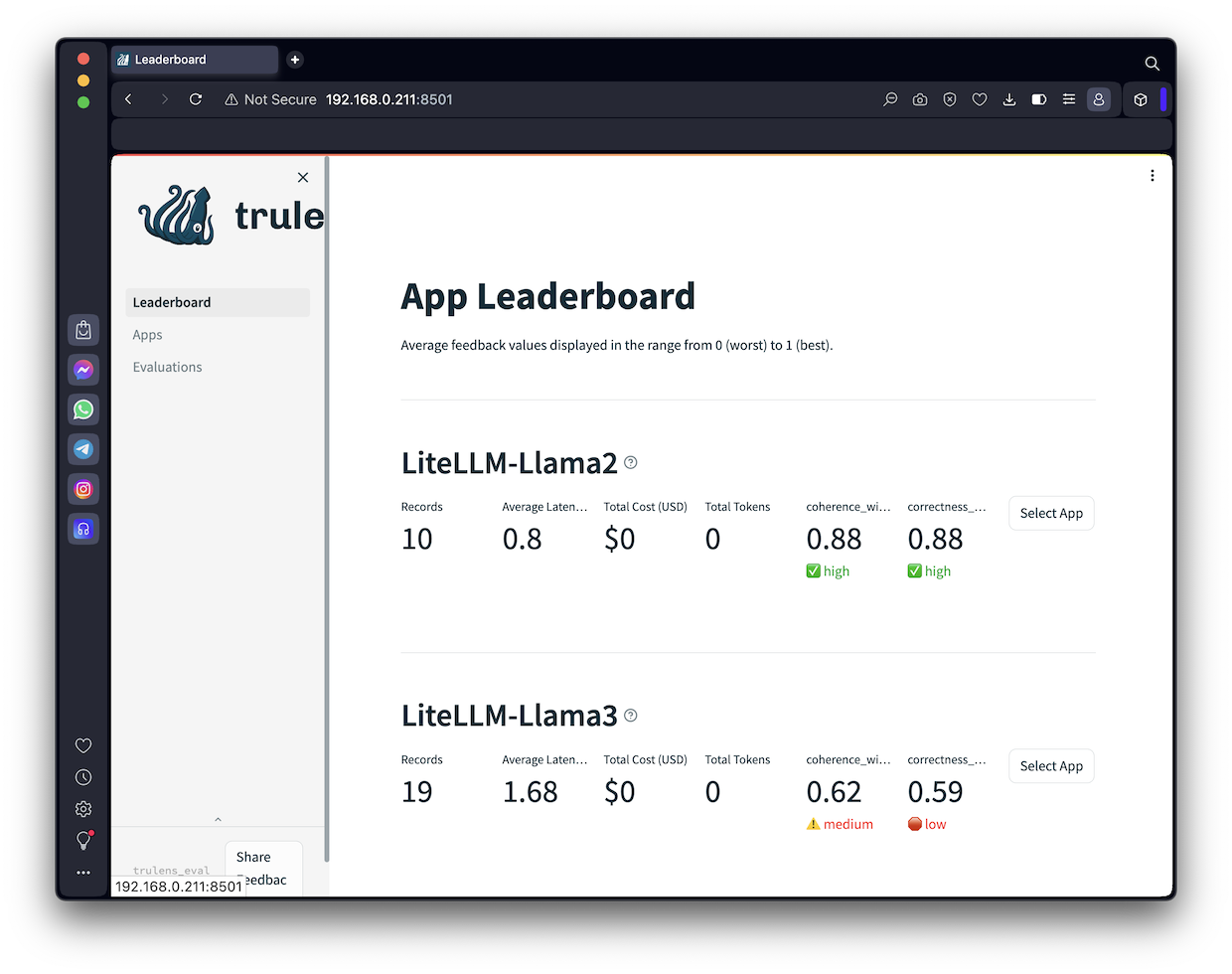
ML 124.1: Leaderboard (10 pts)
On the left side of the Web page, click Leaderboard.The flag is covered by a green rectangle in the image below.
ollama pull llama2
In the "test_llama2.py" script, change all references to llama3 to llama2.
Run the script to test llama2.
When I did it, the resuts were not impressive: llama2 scored better than llama3, as shown below:
ML 124.2: Application Name (5 pts)
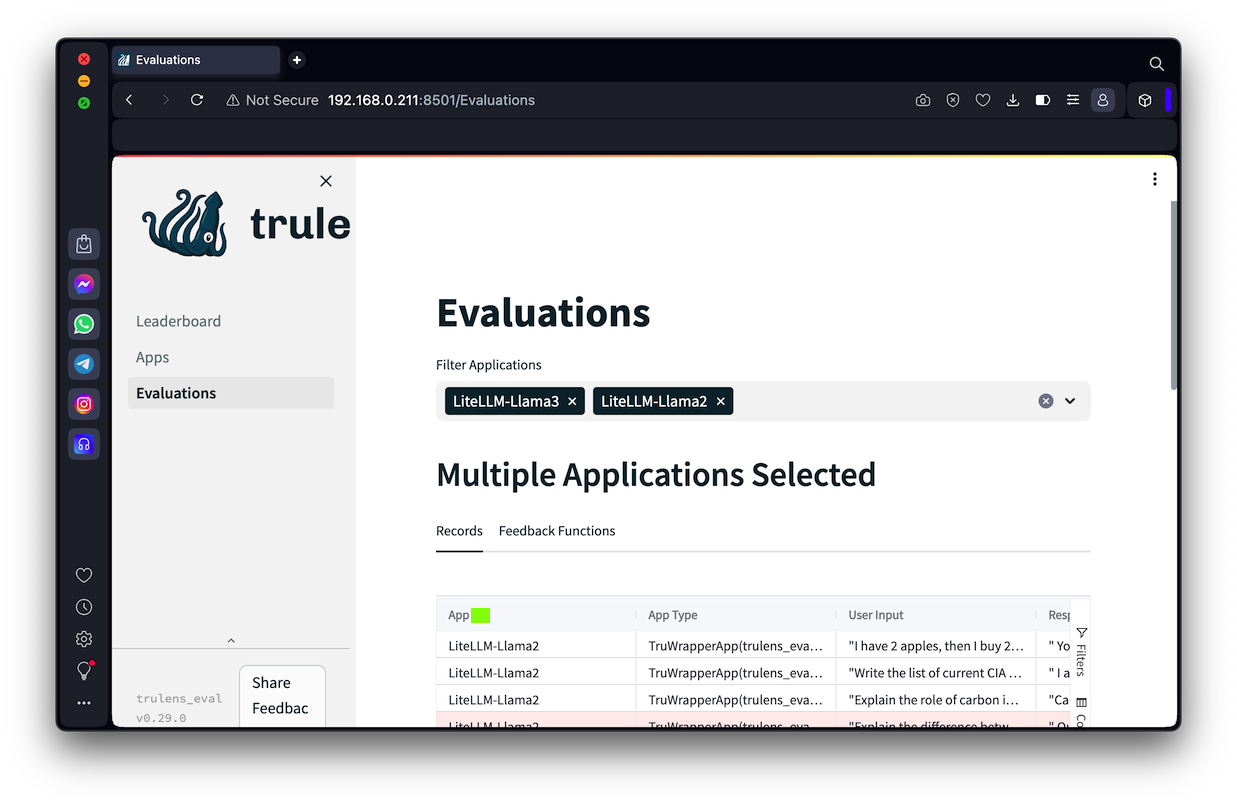
On the left side of the Web page, click Evaluations.The flag is covered by a green rectangle in the image below.