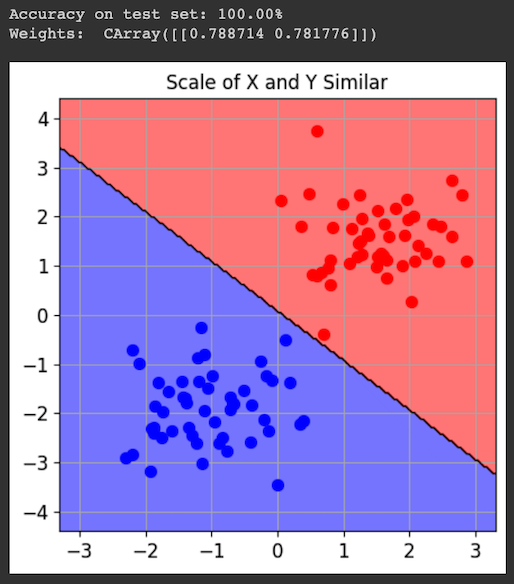
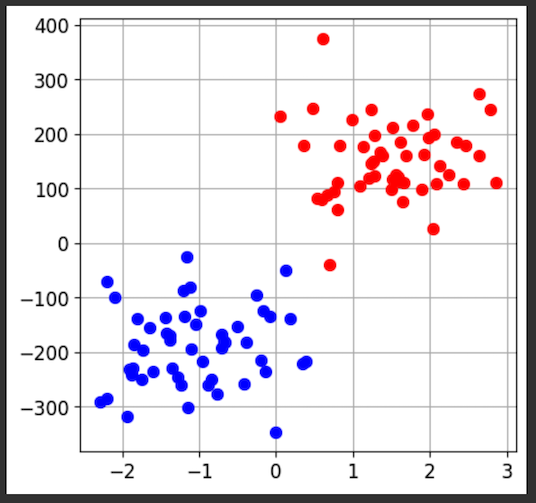
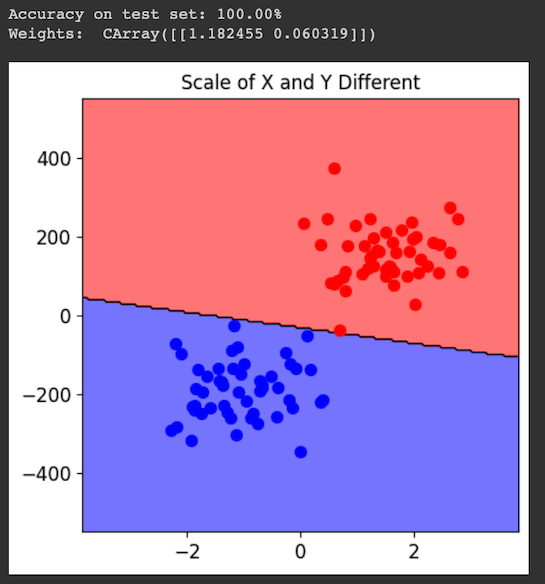
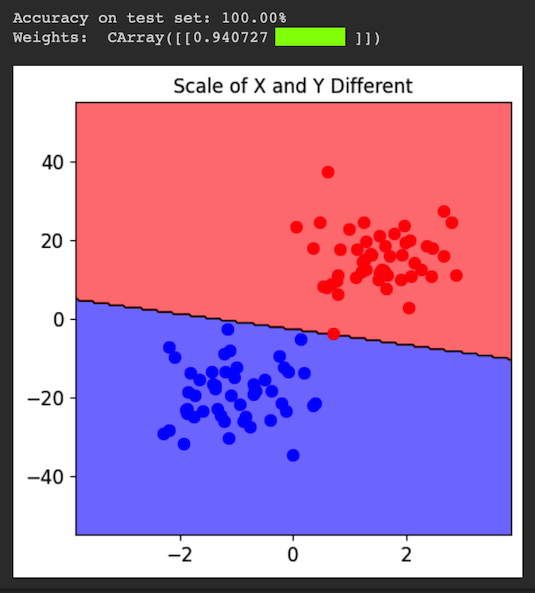
Using SecMLSecML requires an older Python version, which you cannot use in Google Colab. Instead, you must run a local virtual machine running an older version of Debian Linux, by performing the steps below.Installing a HypervisorInstall VMware, as explained here.Downloading a Virtual MachineDownload one of these machines:
The console will tell you how to access the Jupyter server with secml, as shown below. Open a Web browser and go to the URL shown on the console, which will be something like this: http://192.168.0.215:8888/lab/The password is jupyter
|