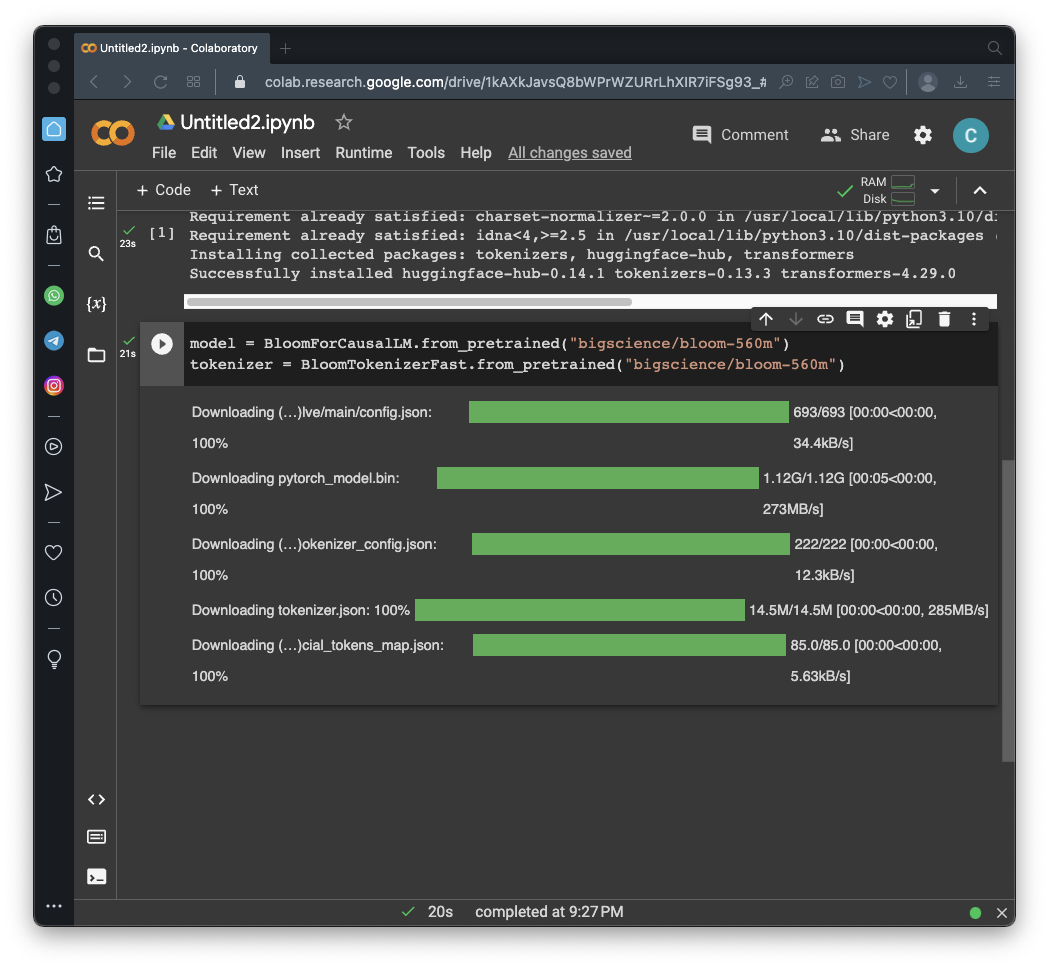
https://colab.research.google.com/If you see a blue "Sign In" button at the top right, click it and log into a Google account.
From the menu, click File, "New notebook".
!pip install transformers
import torch
import transformers
from transformers import BloomForCausalLM
from transformers import BloomTokenizerFast
model = BloomForCausalLM.from_pretrained("bigscience/bloom-560m")
tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom-560m")
prompt = "Why is the sky blue?"
result_length = len(prompt.split()) +50 # Number of words to add
inputs = tokenizer(prompt, return_tensors="pt")
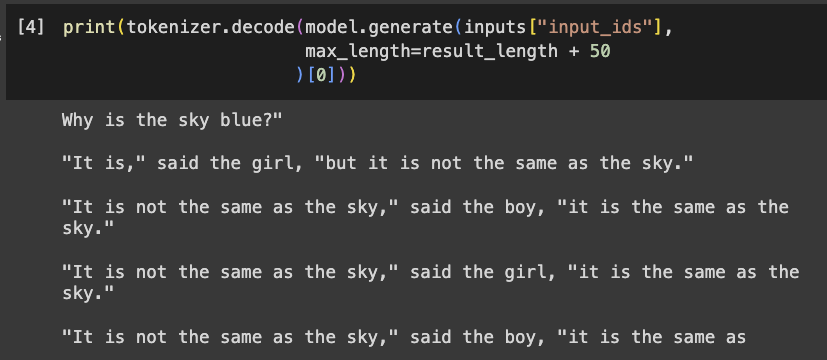
Execute this command to perform a greedy search.
print(tokenizer.decode(model.generate(inputs["input_ids"],
max_length=result_length + 50
)[0]))
Try repeating this calculation--you'll get the same result, because a greedy search has no random variation.
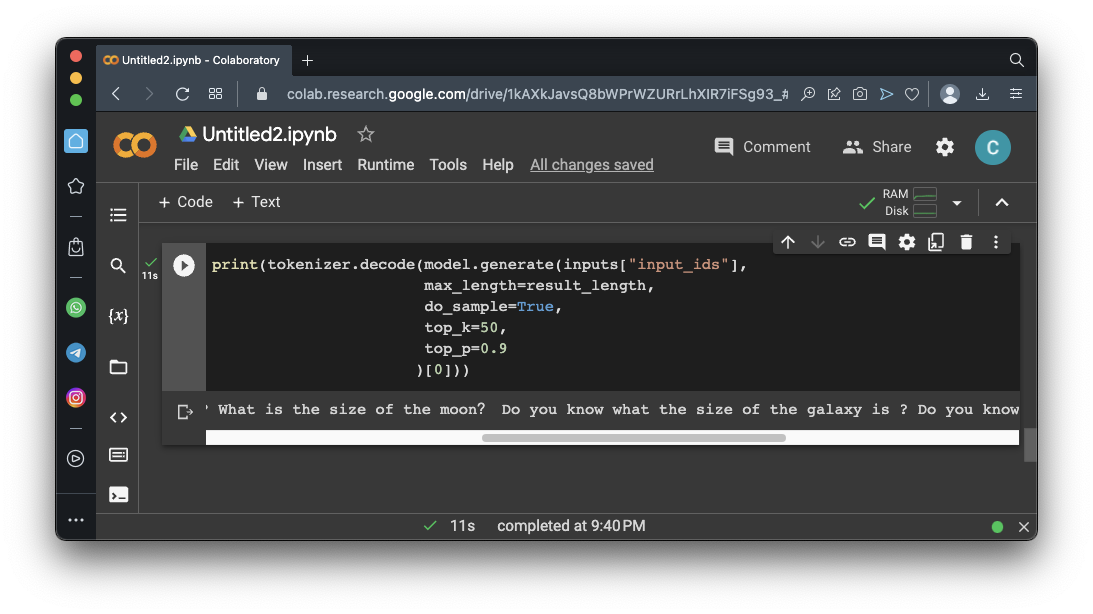
print(tokenizer.decode(model.generate(inputs["input_ids"],
max_length=result_length,
do_sample=True,
top_k=50,
top_p=0.9
)[0]))
Repeat the calculation. The output changes.
print(tokenizer.decode(model.generate(inputs["input_ids"],
max_length=result_length,
num_beams=2,
no_repeat_ngram_size=2,
early_stopping=True
)[0]))
Try repeating this calculation--you'll get the same result, because a beam search also as no random variation, as explained here.
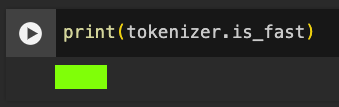
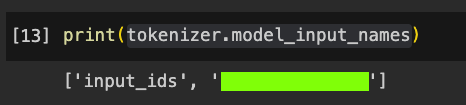
Flag ML 120.5: Tokenizer (10 pts)
Execute this command:The flag is covered by a green rectangle in the image below.
Flag ML 120.6: 1 Billion Parameters (10 pts)
Replace the "bloom-560m" model with the larger "bloom-1b1" model.Execute this command:
The flag is covered by a green rectangle in the image below.
Posted 5-10-23
Third flag updated 10-15-23
Flags 1-4 removed, replaced by flags 5 and 6 12-11-23
Flag 6 image fixed 12-13-23
Descriptions of methods improved 6-29-24