https://colab.research.google.com/If you see a blue "Sign In" button at the top right, click it and log into a Google account.
From the menu, click File, "New notebook".
Enter this code:
import tensorflow as tf
print(tf.__version__)
X = -1, 0, 1, 2, 3, 4
Y = -3, -1, 1, 3, 5, 7
Y = 2*X - 1
Machine learning figures out such relationships.
import tensorflow as tf
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict(np.array([10.0])))
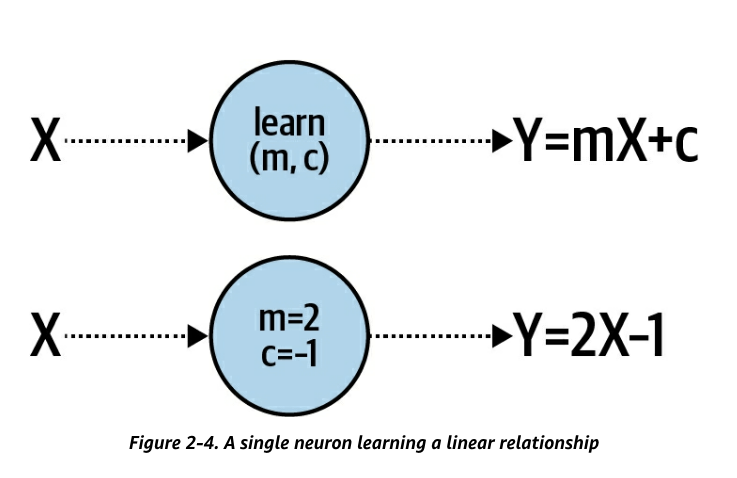
It will then change its guess in the direction of lowering the error and try again.
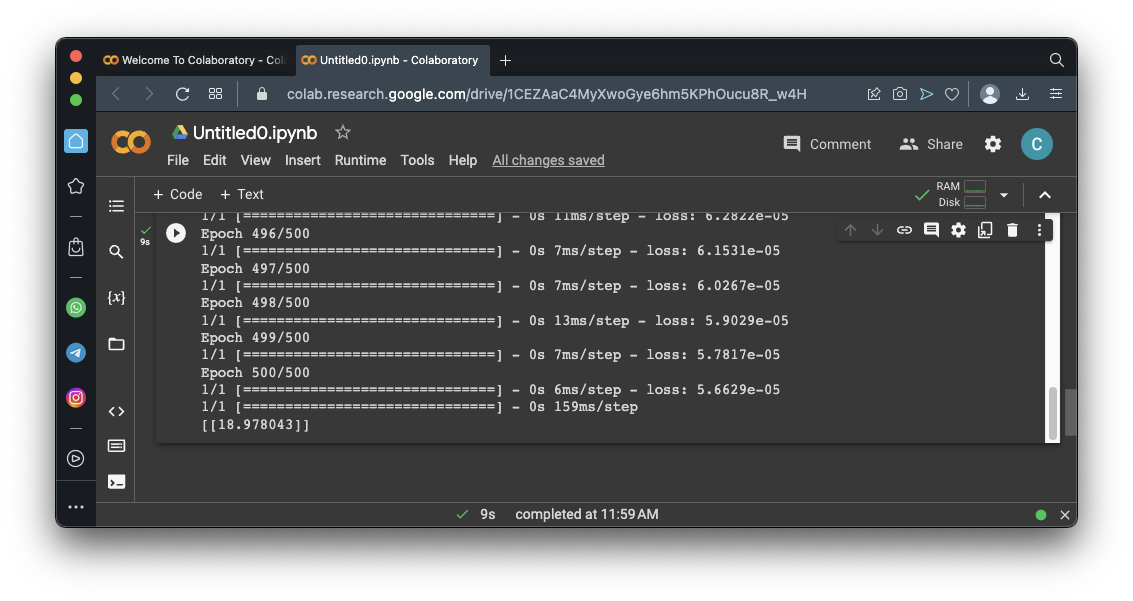
Click the Run button.
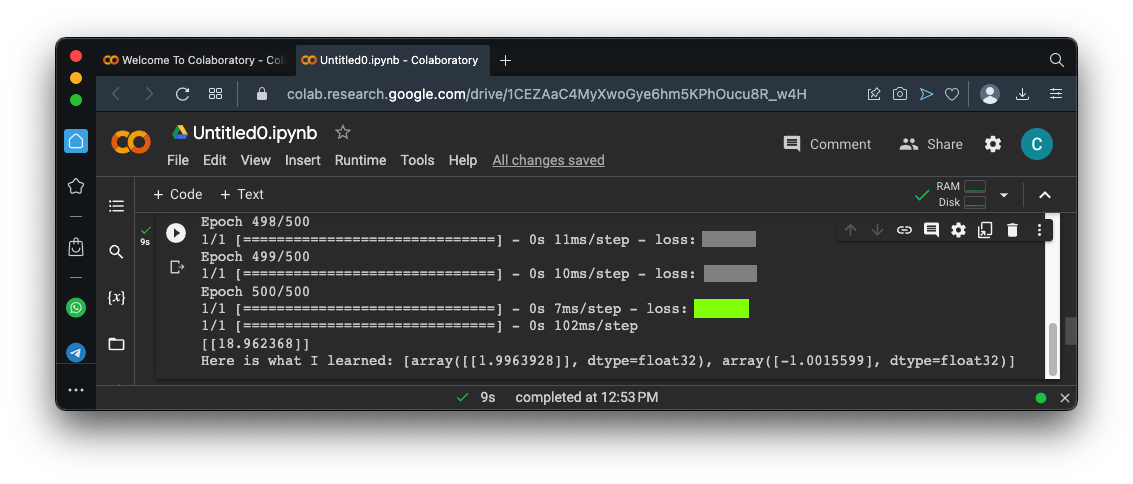
As you can see, the "loss" number at the right end of each row is getting smaller. This is the error value.
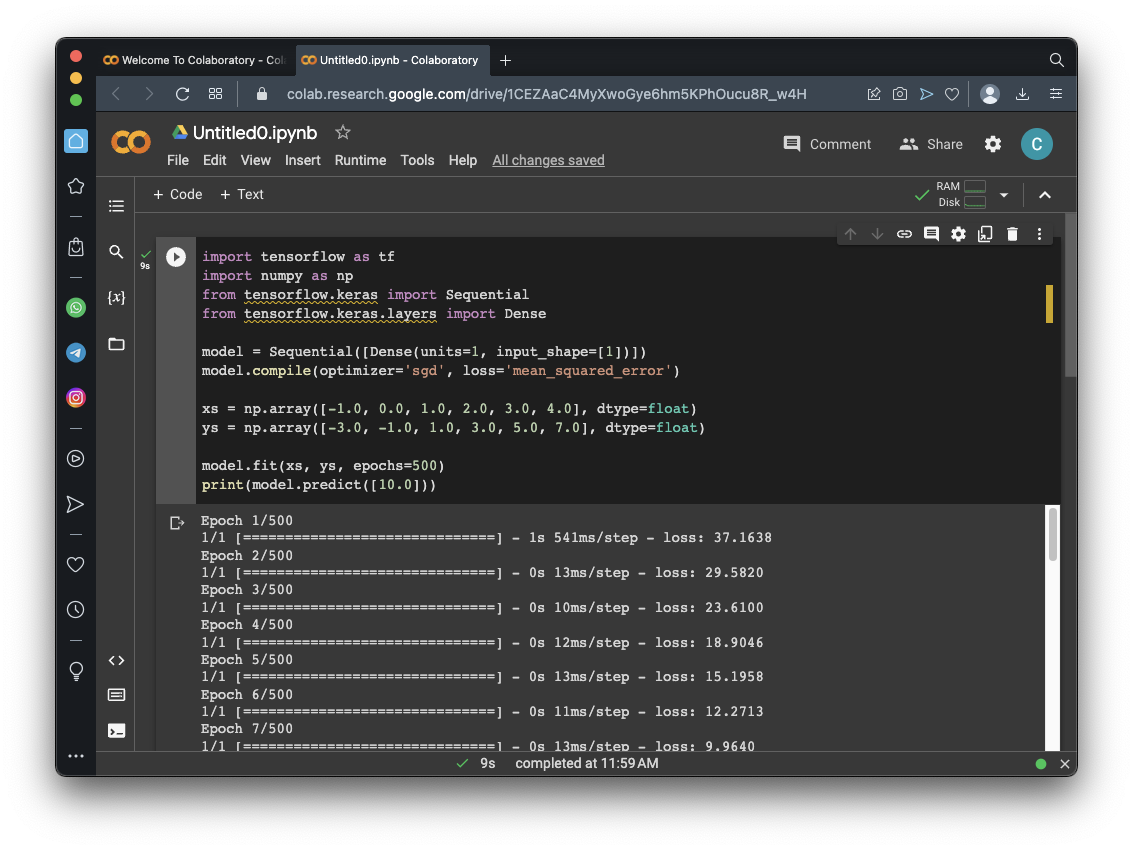
At the end, it prints the model's prediction for Y when X is 10. The correct value is 19, and, as you can see, the model gets very close to it.
import tensorflow as tf
import numpy as np
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
l0 = Dense(units=1, input_shape=[1])
model = Sequential([l0])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict(np.array([10.0])))
print("Here is what I learned: {}".format(l0.get_weights()))
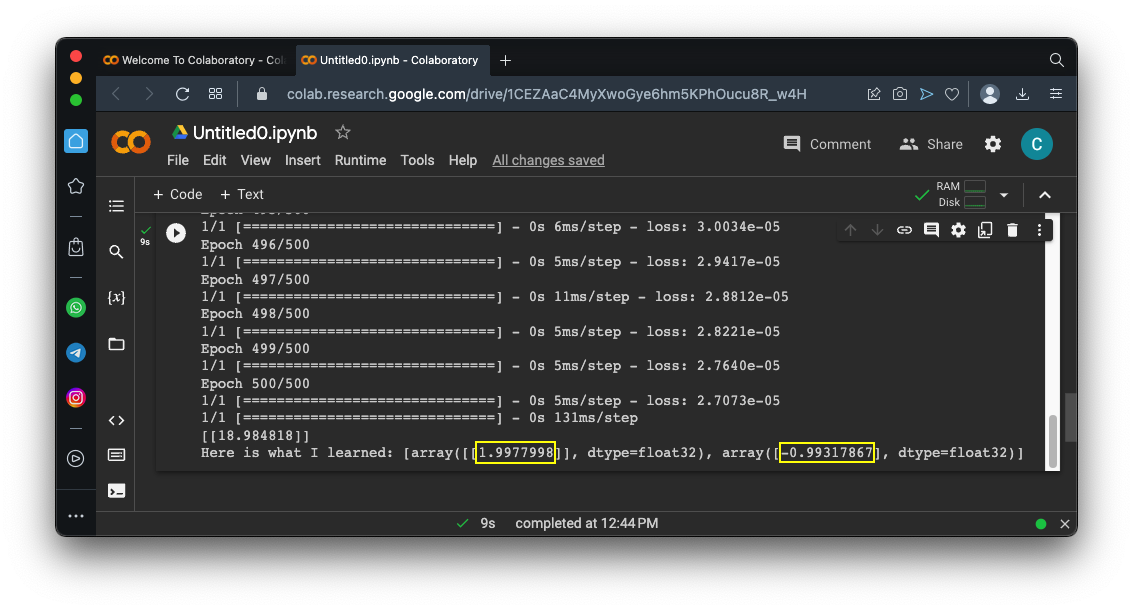
Click the Run button.
Scroll to the bottom of the output.
Remember that the correct relationship between X and Y is:
Y = 2*X - 1
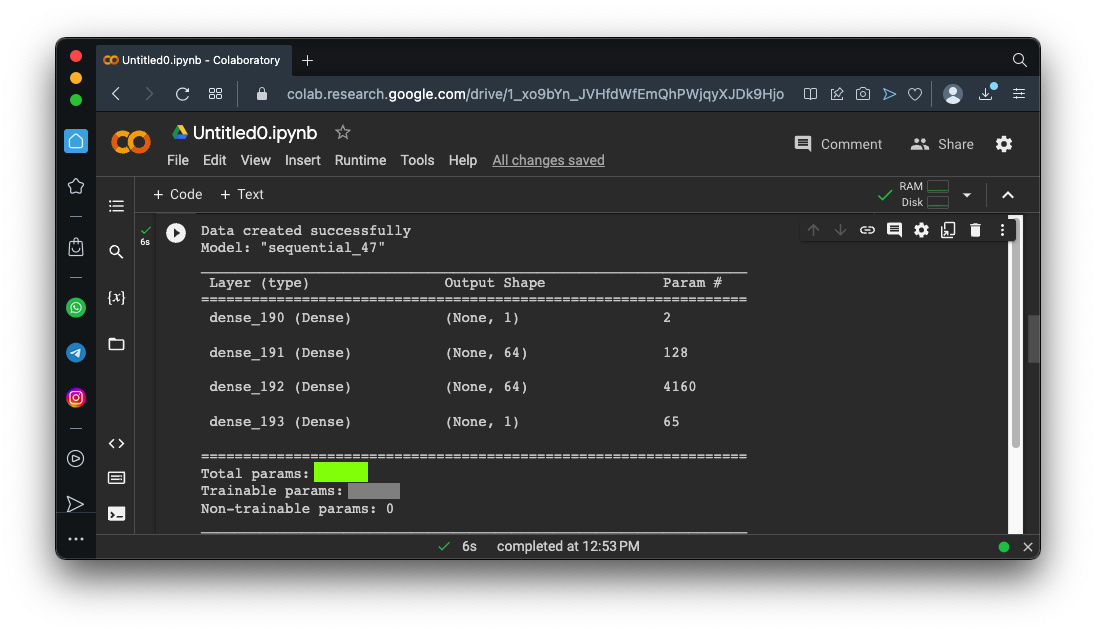
As outlined in yellow in the image below, the model gets very close to the correct weights.
Flag ML 100.1: Learning with Errors (10 pts)
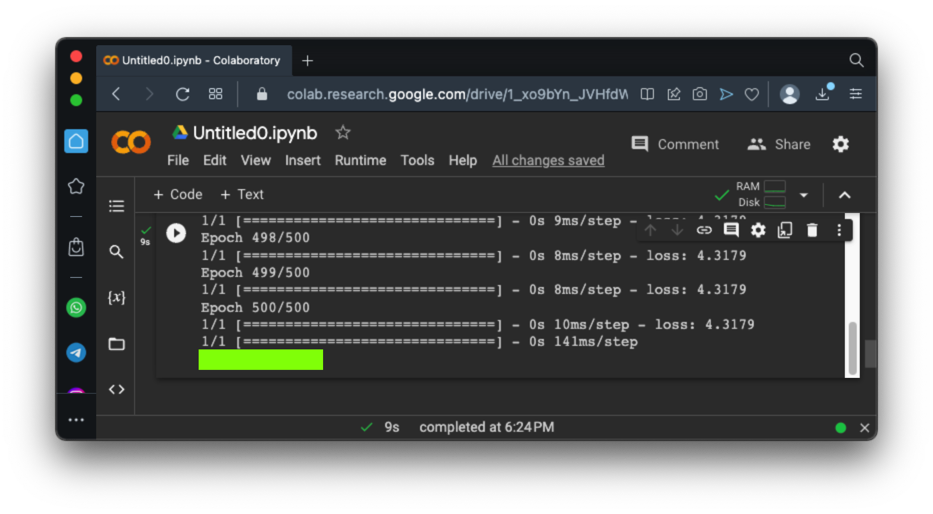
Change the "ys" line to the line shown below, which adds some random errors to the values:The flag is covered by a green rectangle in the image below.
Flag ML 100.2: Fitting a Parabola (10 pts)
We'll use a parabola, defined by:The flag is covered by a green rectangle in the image below.
Flag ML 100.3: Fitting a Complex Curve (10 pts)
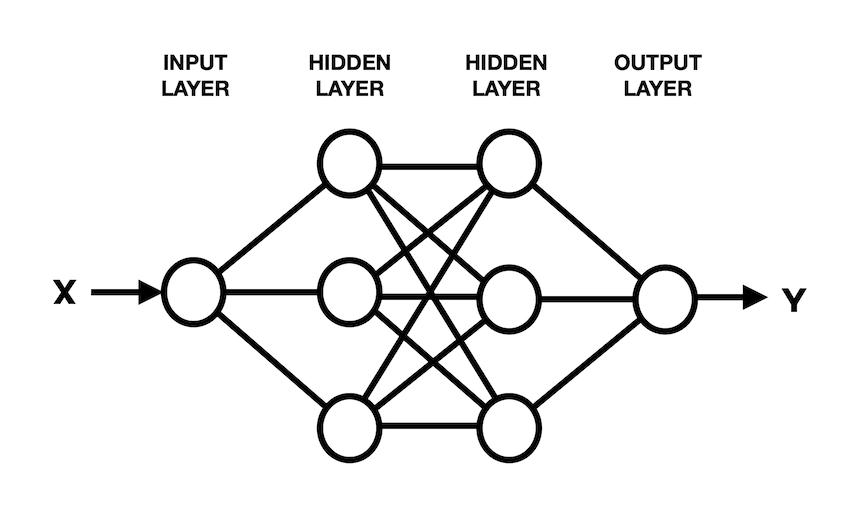
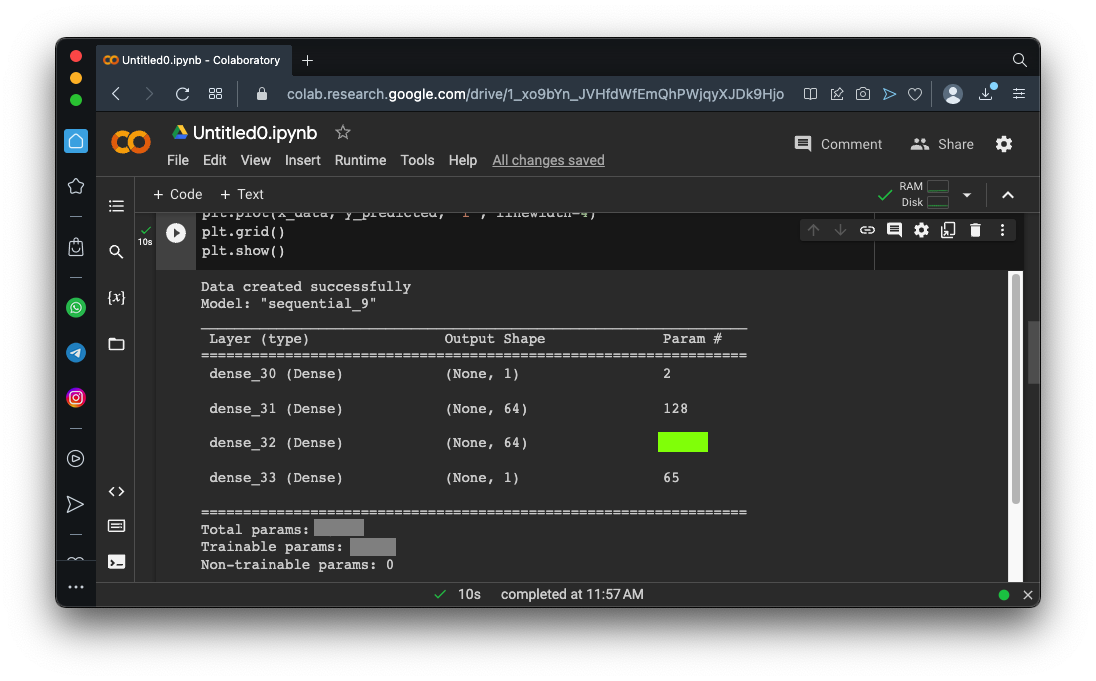
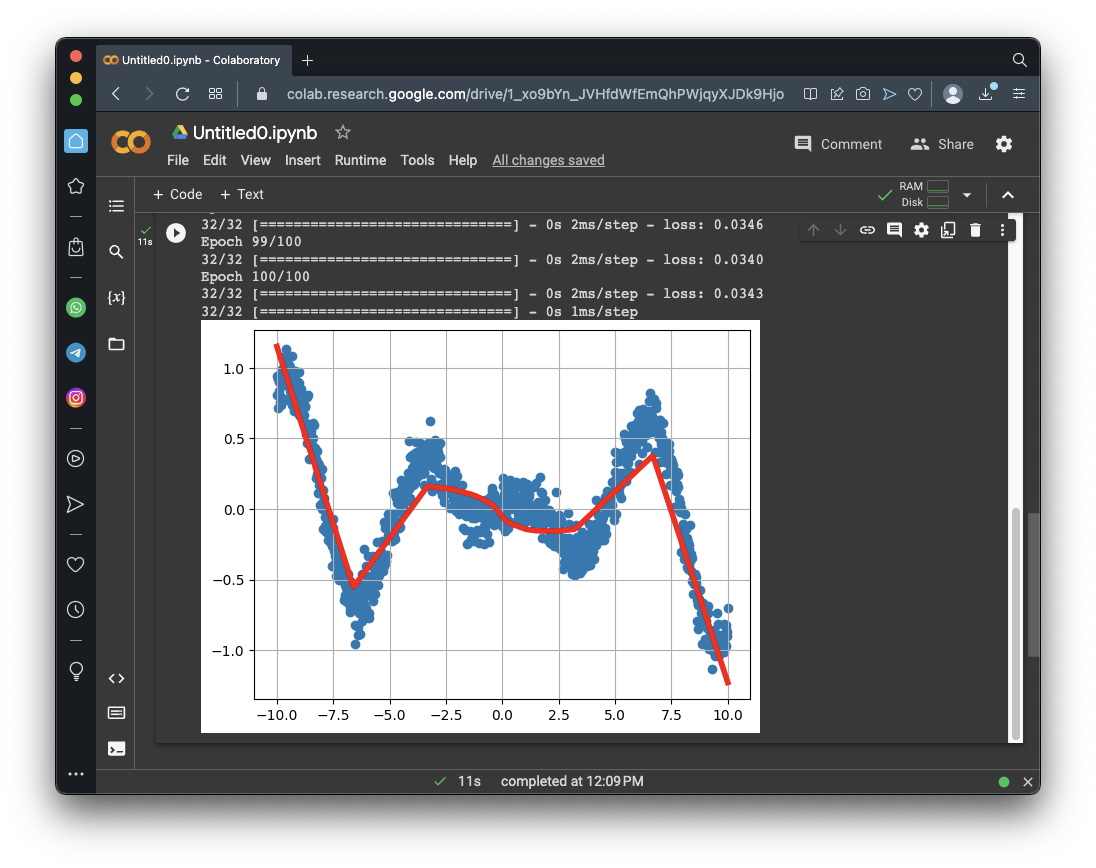
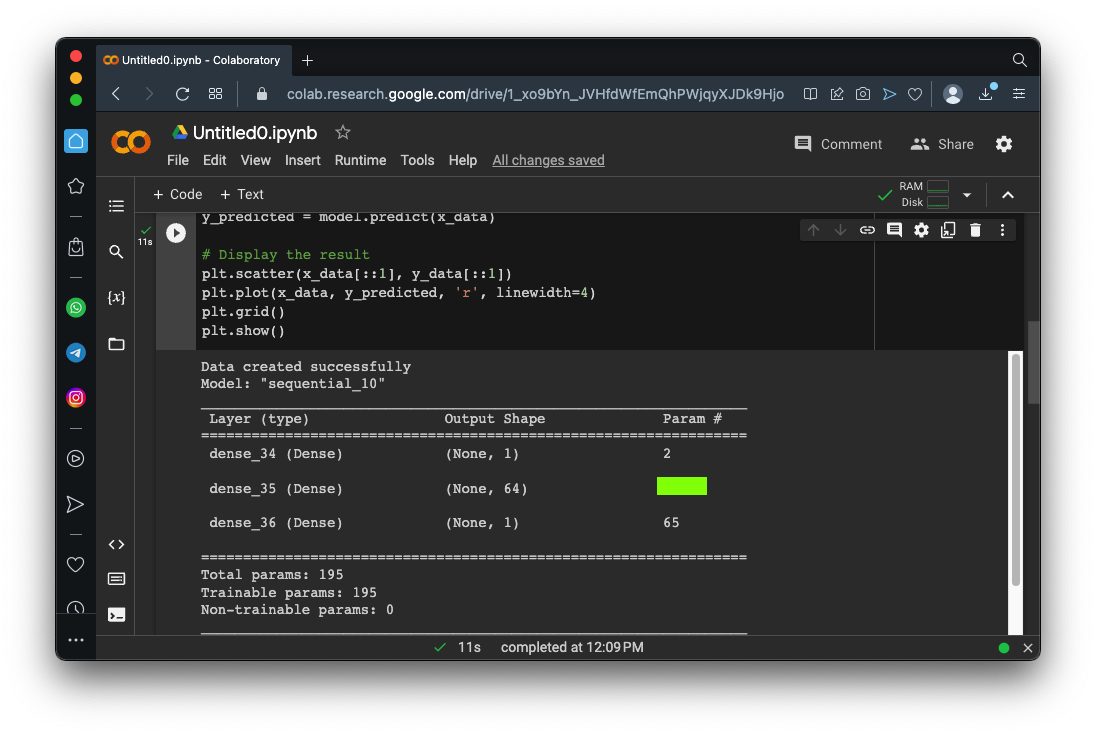
Run this model. It creates 1000 data points on a complex curve with noise, then creates a model with two hidden layers, then trains it and plots the results.Here's a simplified diagram of the model:
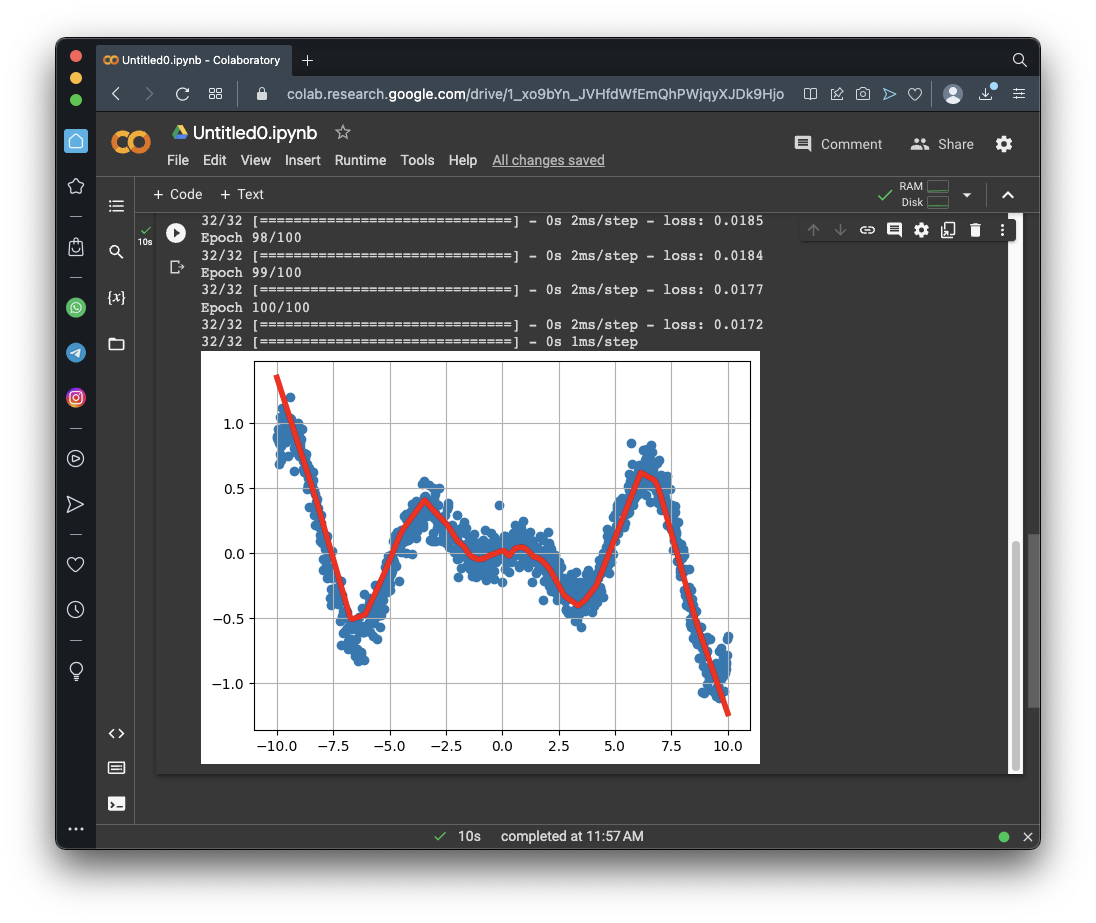
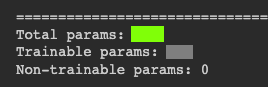
You should see a red line, showing an excellent fit to the blue data points, as shown below.import numpy as np import matplotlib.pyplot as plt from tensorflow import keras from google.colab import files import tensorflow as tf import math # Create noisy data x_data = np.linspace(-10, 10, num=1000) y_data = 0.1*x_data*np.cos(x_data) + 0.1*np.random.normal(size=1000) print('Data created successfully') # Create the model model = keras.Sequential() model.add(keras.layers.Dense(units = 1, activation = 'linear', input_shape=[1])) model.add(keras.layers.Dense(units = 64, activation = 'relu')) model.add(keras.layers.Dense(units = 64, activation = 'relu')) model.add(keras.layers.Dense(units = 1, activation = 'linear')) model.compile(loss='mse', optimizer="adam") # Display the model model.summary() # Training model.fit( x_data, y_data, epochs=100, verbose=1) # Compute the output y_predicted = model.predict(x_data) # Display the result plt.scatter(x_data[::1], y_data[::1]) plt.plot(x_data, y_predicted, 'r', linewidth=4) plt.grid() plt.show()Scroll up to the start of the output to see a diagram of the model. The flag is covered by a green rectangle in the image below.
Flag ML 100.4: Using Fewer Layers (5 pts)
Run the model above, but add a "#" in front of one of these lines:The fit is still pretty good, as shown below.Scroll up to the start of the output to see a diagram of the model. The flag is covered by a green rectangle in the image below.
Flag ML 100.5: Varying units and layers (15 pts)
Start with the code for ML 100.3, and run it with these variations:For each variation, run it three times and note the "loss" value for the fully trained model. Find the model with the lowest average loss after training--that's the best model.
- 32 units per layer, one hidden layer
- 16 units per layer, two hidden layers
- 4 units per layer, 3 hidden layers
- 4 units per layer, 4 hidden layers
Scroll up to the start of the output to see a diagram of the best model. The flag is covered by a green rectangle in the image below.
Flag ML 100.6: Varying input data and noise (15 pts)
Start with the code for ML 100.3. Notice lines of code shown below.
The number of points is 1000, outlined in yellow in two places.
The amount of noise is 0.1, outlined in red.Try these combinations:
For each variation, run it three times and note the "loss" value for the fully trained model. Find the model with the lowest average loss after training--that's the best model.
- 100 points, noise 0.1
- 1000 points, noise 0.5
- 300 points, noise 0.01
Scroll up to the start of the output to see a diagram of the best model. The flag is covered by a green rectangle in the image below.
Posted 4-10-23
Extra data removed from challenges 5 and 6 4-12-23
Video updated 4-20-23
Model diagram added to flag 3 on 8-8-24
print line updated to "print(model.predict(np.array([10.0])))" for recent tensorflow version 8-9-24