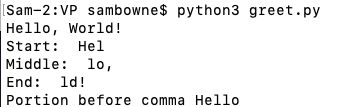
nano greet.py
greet = "Hello, World!"
print(greet)
print("Start: ", greet[0:3])
print("Middle: ", greet[3:6])
print("End: ", greet[-3:])
a = greet.find(",")
print("Portion before comma", greet[:a])
Execute this command to run the program:
python3 greet.py
Examine the output to make sure you understand how to cut out portions of a string, and how to find substrings within a string.
Here is a handy reference:
In a text editor, create a file named echo.py containing this code, as shown below:
import socket
s = socket.socket()
s.connect(("ad.samsclass.info", 10201))
print(s.recv(1024).decode())
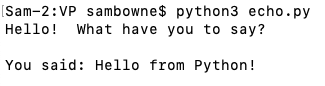
s.send("Hello from Python!\n".encode())
print(s.recv(1024).decode())
s.close()
Run the program, as shown below. It sends the string "Hello from Python!" to the server, which echoes it back.
Explanation
import socket import the "socket" library, which contains networking functions s = socket.socket() create a socket object named "s" s.connect(("ad.samsclass.info", 10201)) connect to the server "ad.samsclass.info" on port 10201 s.recv(1024) receive data from the server, up to a maximum of 1024 characters s.send("Hello from Python!\n".encode()) send data to the server s.close() close the connection and destroy the "s" object
Flag VP 100.1: Goodbye (5 pts)
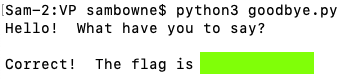
Connect to the ad.samsclass.info server on port 10202.Send it the string "Goodbye".
When you do, you will receive a flag, covered by a green box in the image below.
Flag VP 100.2: Increment (10)
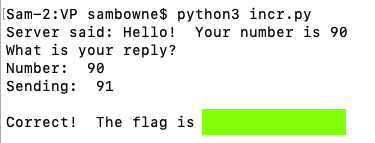
Connect to the ad.samsclass.info server on port 10203.It sends you a number. Add one to that number and send it to the server.
When you do, you will receive a flag, covered by a green box in the image below.
Hint: Python String to Int() Tutorial
for i in range(3):
print(i)
print()
for c in "CAT":
print(c)
Notice that a colon starts a loop, and that every statement in a loop must be indented.
You can read more about loops in this tutorial.
Flag VP 100.3: Add and Subtract (25)
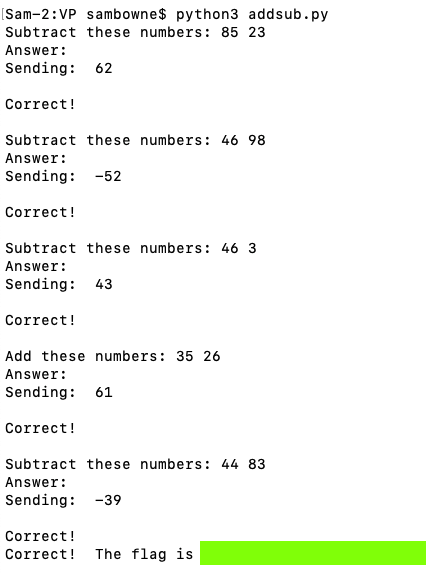
Connect to the ad.samsclass.info server on port 10204.Combine two numbers as required and send the result.
You have to get all five answers correct within five seconds to get the flag, covered by a green box in the image below.
Hint: Only connect once. If you connect five times, you'll always be solving the first challenge, and never see the flag.
So in Python 2, you can store data like this:
Let's see how that works in Python 3.
Execute this command to open Python 3 in interactive mode:
python3
a = '\x41\x42\xff'
a
a[0]
a[1]
a[2]
To see the bytes used to store the string, execute these commands:
b = a.encode()
hex(b[0])
hex(b[1])
hex(b[2])
hex(b[3])
What's going on?
So the character '\xff' in the string is interpreted a Unicode Code Point, and it's stored in two bytes, as shown below:
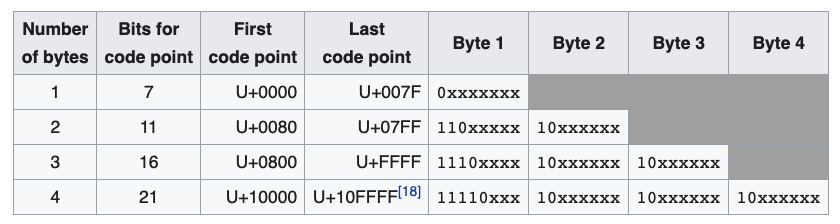
UTF-8 characters have variable length, from one to four bytes. This means they can be used to print a lot of useful characters,
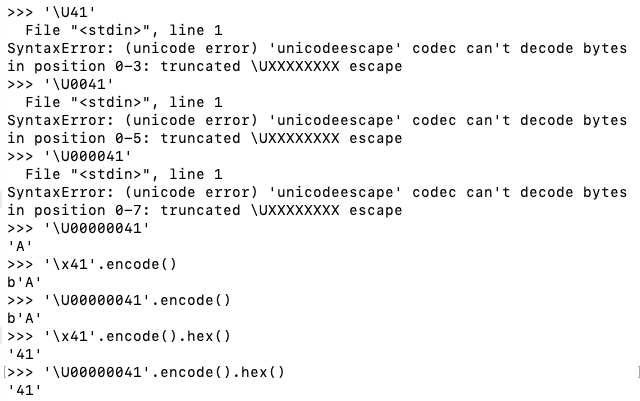
Execute these commands:
'\x41'
'\U41'
'\U0041'
'\U000041'
'\U00000041'
'\x41'.encode()
'\U00000041'.encode()
'\x41'.encode().hex()
'\U00000041'.encode().hex()
Execute these commands:
'\xff'
'\Uff'
'\U00ff'
'\U0000ff'
'\U000000ff'
'\xff'.encode()
'\U000000ff'.encode()
Unicode code point values are not identical to their binary representations in memory.
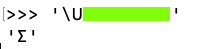
Flag VP 100.4: Greek (5)
Find the eight-character Unicode code point for a capital Sigma, covered by a green box in the image below.
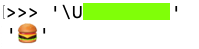
Flag VP 100.5: Burgertime (5)
Find the eight-character Unicode code point for a hamburger, covered by a green box in the image below.